A resilient, Zookeeper-less Solr architecture on AWS
The Recommendations team is back, providing a design for deploying Solr on AWS.

Software Developer – Recommender Systems
Since last year, Zalando has sped up its adoption of cloud-provided, on-demand infrastructure; we decided to embrace AWS. This meant teams would be given more freedom by being allowed to administer their own AWS accounts. In addition to this, we were presented with a useful set of tools called STUPS.
Explaining STUPS in detail would require a whole blog post in itself! To summarise – it is a combination of client- and server-side software that essentially allows you to provision complicated sets of hardware and deploy code to them, all with a single shell command.
With the freedom of being able to provision our own hardware in a cloud environment, we knew that we needed to start gracefully handling hardware failures. There is no safety net, no team of first responders that will get your system back up if a drive or server fails.
The primary problem we face is that EC2 instances are not guaranteed to stay up forever. AWS will sometimes announce instance terminations in advance, but terminations and reboots can also happen unannounced. Furthermore, disk volumes, both internal storage and EBS, may fail suddenly and get remounted on your instance in read-only mode.
Here are some challenges we set out to solve while designing a Solr deployment for the Recommendations team.
Challenges
There are two main challenges we face when deploying Solr on AWS. They are:
- Bootstrapping a cluster and,
- Dealing with hardware failures
Let’s look at these in a bit more detail.
Bootstrapping a cluster
Here at the Recommendations team, we run classical master-slave Solr configurations. Furthermore, we separate the write path entirely from the read path. In essence, we have a service dedicated solely to gathering the data, preparing it and, finally, indexing it in Solr. Other services will in turn read and use this data while serving recommendations to our customers.
To bootstrap a complete Solr deployment and make it available for reads, we need to:
- Create a single master instance
- Fill it with data
- Create a farm of slave instances and,
- Replicate the master’s data to the slaves continuously
In addition, the size of the data needs to be considered, and a decision on the necessity of sharding must be made. In the use case this system was supporting, all of the data could fit on one machine, so no sharding was necessary. Even in the age of Big Data, it turns out that many use cases’ data sets can be condensed into sizes that would be more appropriately named “medium data”.
Dealing with hardware failures
In Zalando’s data center deployments, we were relying on hardware failures being handled by the data center’s incident team. The failover was being handled by the Recommendations team in cooperation with a centralised system reliability team.
On AWS however, we are on our own. Therefore, it was necessary to build a Solr architecture that would fail gracefully and continue working without human intervention for as long as possible. Because our team does not have engineers on call, we wanted to be able to react hours or even days later, without impacting customer satisfaction.
Implementation: The old architecture
Let’s take a look at the state of the data center. The indexing was managed by an application that first indexed the master and then forced the slaves to replicate.

This way, our batch updates could be executed in a one-shot procedure. The read path was separate, as shown in the following diagram.

It would be possible to mirror the same setup on AWS:
- Every Solr instance would be running in its own Docker container on its own EC2 instance
- The Writer app would need to keep the IP address of the master, and the Reader apps would need to keep a set of all the slave’s addresses
Here we stumble upon the first problem: EC2 instances get a new random IP address when they are started. The addresses kept by the apps would therefore need to be updated whenever an instance fails or another instance is added. Doing this manually was not an option.
Handling ephemeral IP addresses
The problem of having basically ephemeral addresses can be solved by the SolrCloud feature, first introduced in Solr 4. However, SolrCloud requires an external service to keep track of the currently available machines and their IPs: Zookeeper.
In an effort to cut down the complexity of our Solr deployment, we decided to try to implement a solution without Zookeeper. As you will see, the proposed architecture makes heavy use of AWS’s Elastic Load Balancers.
The new architecture
Let’s take a look at the proposed new AWS architecture.

The architecture makes use of three distinct load balancers:
- Indexing ELB
- Replication ELB and,
- Query ELB
Indexing ELB
The indexing ELB is the only address required by the Writer app. It always points to the single Solr master instance running behind it. The Writer app uses this address to index new data into Solr.
The Solr master runs in a one-instance Auto-Scaling Group (ASG), which reacts to a simple EC2 health check. If the Solr master shuts down, the EC2 check will fail and the Writer app will know not to try and index it. When the master comes back up, i.e. the EC2 health checks stop failing, it will be empty and the Writer app will know it can now index it with fresh data.
Replication ELB
The replication ELB is the second ELB connected to Solr master’s one-instance ASG. It uses an ELB health check. The health check points to a custom URL endpoint served by Solr. When the check calls this endpoint, it executes Java code that examines the contents of the Solr cores: It checks if the cores contain enough data to be considered ready for replication.
The slaves are configured so that their master URL points to the replication ELB. They will continuously poll the master through this ELB to check for changes in the data and to replicate once changes are detected.
Query ELB
The query ELB checks the exact same condition as the replication ELB. It checks if the slaves’ cores are full, i.e. successfully replicated from master and if so, the slave can join the query ELB’s pool.
Implementing the ELB health check
To implement the check used by the replication and query ELBs, we need to extend Solr with some custom code.
It’s necessary to implement a new controller that will expose the /replication.info endpoint that will be used by the replication and query ELBs. Here’s a sample showing how this can be achieved:
@Controller
public final class ReplicationController {
private static final int MIN_DOC_COUNT = 1000;
@RequestMapping("/replication.info")
@ResponseBody
public ResponseEntity replicationInfo(final ServletRequest request) {
final CoreContainer coreContainer = (CoreContainer) request.getAttribute("org.apache.solr.CoreContainer");
for (final SolrCore core : coreContainer.getCores()) {
final int docCount = getDocCount(core);
if (docCount < MIN_DOC_COUNT) {
return new ResponseEntity<>("Not ready for replication/queries.", HttpStatus.PRECONDITION_FAILED);
}
}
return new ResponseEntity<>("Ready for replication/queries.", HttpStatus.OK);
}
}
The simplest way to implement the getDocCount method could be something like this:
private int getDocCount(final SolrCore core) {
RefCounted newestSearcher = core.getNewestSearcher(false);
int docCount = newestSearcher.get().getIndexReader().numDocs();
return docCount;
}
In this example code we see that the /replication.info endpoint will return 200 OK if all the cores in Solr have at least a thousand documents. However, if a single core is found to not satisfy this condition, the HTTP status 412 is returned, thus instructing the ELB that this instance is not healthy, i.e. does not contain all necessary data. Of course, the logic can be extended to include more complex rules if the use case requires them.
Scenario: Failure of the master instance
Failure of Solr master results in two negative outcomes:
- Writer app is unable to update the master with fresh data and,
- Slaves cannot replicate anymore because the Replication ELB health check failure leads to the master being taken out of the Replication ELB’s pool.

Both outcomes are not critical because as soon as the master is taken out of the Replication ELB, slaves get to keep their old data and can happily continue to serve requests.
But a bigger risk comes when the master is automatically replaced by the ASG. The new master instance is started whilst empty and remains empty until the Writer app indexes it again. If no precautions were taken, the slaves would replicate the empty cores from our new master instance. This danger is avoided by keeping the master out of the replication ELB for as long as it does not have all cores ready, as shown in the diagram below.
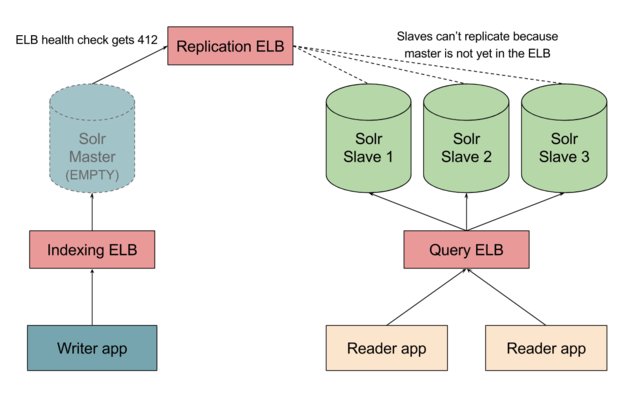
Only after the master is fully indexed can the slaves continue to replicate fresh data.
Scenario: Failure of slave instances
A failure of a slave instance is a simpler scenario. As soon as the instance becomes unavailable, its health checks fail and it is taken out of the query ELB’s pool. The slave instances’ ASG knows to immediately replace it and a new, empty slave instance is started.
The procedure is very similar to the master instance example we explained above. The new slave instance remains outside of the query ELB’s pool for as long as it is still replicating the data, i.e. for as long as it still returns 412 to the ELB’s health check.
Once the ELB’s /replication.info health check determines that the new instance has replicated all necessary data, the instance is added to the ELB pool and begins serving read queries.
It is also worth mentioning that it is very important to set an appropriate grace period on the slaves’ ASG. The replication requires some time, and it is necessary to make the grace period long enough for the replication of data to complete before the health checks are started. If a slave does not replicate within this time, it will start returning 412s and will be deemed unhealthy, terminated, and replaced with another instance, thus opening up the possibility of never being able to fully replicate before termination.
Thanks for reading. I hope you found this Solr architecture interesting. I’m open to questions, suggestions and general comments. You can find me on Twitter.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Software Engineer!






