About Akka Streams
Pipeline processing on a high level with Akka Streams and our Helsinki Engineering Team.

Software Engineer
In many computer programs, the whole logic (or a vast part of it) is essentially the step-by-step processing of data. Of course, this includes the situation when we iterate over the data and just execute the processing logic on every piece of it. However, there are a couple of complications here:
- The processing logic may be quite complex, with various aggregations, merging, routing, error recoveries, etc.
- We might want to execute steps asynchronously, for instance, to take advantage of multiprocessor machines or use I/O
- Asynchronous execution of data processing steps inherently involves buffering, queues, congestion, and other matter, which are really difficult to handle properly (read “Handling Overload” by Fred Hébert)
Therefore, sometimes it is a good idea to express this logic on a high level using some kind of a framework, without a need to implement (possibly complex) mechanics of asynchronous pipeline processing. This was one of the rationales behind frameworks like Apache Camel or Apache Storm.
Actor systems like Erlang or Akka are fairly good for building robust asynchronous data pipelines. However, they are quite low-level by themselves, so writing such pipelines might be tiresome. Newer versions of Akka include the possibility of doing pipeline processing on quite a high level, called Akka Streams. Akka Streams have grown from the Reactive Streams initiative. It implements a streaming interface on top of the Akka actor system. In this post I would like to give a short introduction to this library.
We will need a Scala project with two dependencies:
"com.typesafe.akka" %% "akka-actor" % "2.4.14",
"com.typesafe.akka" %% "akka-stream" % "2.4.14"
Akka Streams basics
In Akka Streams, we represent data processing in a form of data flow through an arbitrary complex graph of processing stages. Stages have zero or more inputs and zero or more outputs. The basic building blocks are Sources (one output), Sinks (one input) and Flows (one input and one output). Using them, we can build arbitrary long linear pipelines. An example of a stream with just a Source, one Flow and a Sink:
val helloWorldStream: RunnableGraph[NotUsed] =
Source.single("Hello world")
.via(Flow[String].map(s => s.toUpperCase()))
.to(Sink.foreach(println))
I think the idea is quite obvious: a single string value goes from its Source through a mapping stage Flow[String].map and ends up in a Sink that printlns its input.
We can also use some syntactic sugar and write mapping in a more simple way:
val helloWorldStream: RunnableGraph[NotUsed] =
Source.single("Hello world")
.map(s => s.toUpperCase())
.to(Sink.foreach(println))
However, if we execute this code, nothing will be printed. Here lies the border between streams description and streams execution in Akka Streams. We have just created a RunnableGraph, which is kind of a blueprint, and any other (arbitrary complex) streams are only blueprints as well.
To execute, materialize (in Akka Streams’ terms) them, we need a Materializer — a special tool that actually runs streams, allocating all resources that are necessary and starting all the mechanics. It is theoretically possible to have any kind of Materializer, but out of the box, the library includes only one, ActorMaterializer. It executes stream stages on top of Akka actors.
implicit val actorSystem = ActorSystem("akka-streams-example")
implicit val materializer = ActorMaterializer()
Now, having this Materializer implicitly accessible in the scope, we can materialize the stream:
helloWorldStream.run()
It will print HELLO WORLD to the console.
We can do this as many times as we like, and the result will be the same — blueprints are immutable. There are many more interesting stages out of the box:
- Various Sources (like Source.fromIterator, Source.queue, Source.actorRef, etc.)
- Various Sinks (like Sink.head, Sink.fold, Sink.actorRef, etc.)
- Various Flows (like Flow.filter, Flow.fold. Flow.throttle, Flow.mapAsync, Flow.delay, Flow.merge, Flow.broadcast, etc.), many of them are available via simple DSL (like .map, .filter, etc.)
Check out the overview of built-in stages and their semantics page in the documentation.
The cool thing about Akka Streams building blocks is that they are reusable and composable. Here is an example of compositions taken from the Modularity, Composition and Hierarchy page in the documentation:
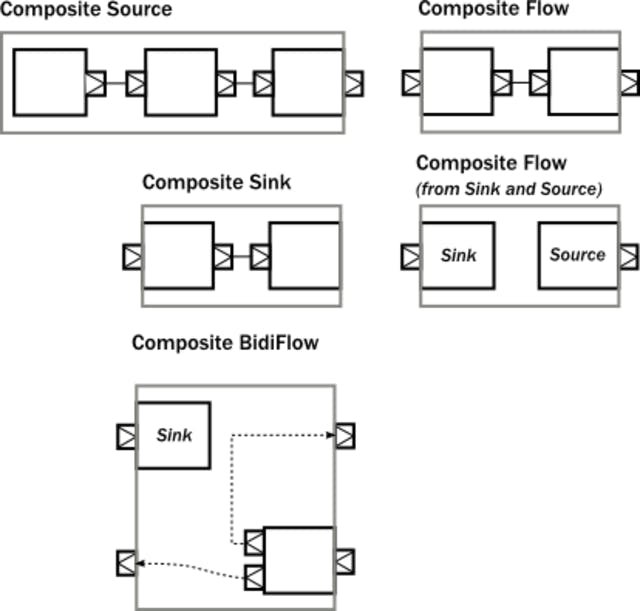

Materialized values and kill switches
One of the concepts that deserve attention here is materialized values. Let us rewrite the last line of code just a little:
val materializedValue: NotUsed = helloWorldStream.run()
I just added the val with a type NotUsed, the same NotUsed we just have seen as a type parameter of the RunnableGraph earlier. As we can see, the value of this type has been created and returned during the materialization — any materialization. Run a stream five times — get five materialized values, completely independent.
Materialized values (and their type) originate in a Source and are propagated through all stages of a stream to a Sink. We can modify this behaviour and create other materialized values.
But what is interesting in this NotUsed? Little, in fact, so let us make it more useful:
val helloWorldStream: RunnableGraph[Future[Done]] =
Source.single("Hello world")
.map(s => s.toUpperCase())
.toMat(Sink.foreach(println))(Keep.right)
val doneF: Future[Done] = helloWorldStream.run()
doneF.onComplete {
case Success(Done) =>
println("Stream finished successfully.")
case Failure(e) =>
println(s"Stream failed with $e")
}
Here we replaced to with toMat. toMat allows a materialized value provided by a Sink to be used. In this case, the materialized value of Sink.foreach is Future[Done], a Future that completes with Success[Done] when a stream finishes (its materialization, to be precise) successfully, and with Failure when it fails. Done is just a signalling object that brings no information inside. We can think of materialized values as of some kind of external handler to a materialized stream.
toMat takes the additional parameter combine, a function that combines two materialized values: one from the previous stage and one from the current stages. There are four predefined functions: Keep.left (used by default, check the implementation), Keep.right, Keep.both and Keep.none. It is, of course, possible to use a custom function with arbitrary combining logic.
This is a good place to introduce another useful concept — kill switches. This is an object used externally to stop the materialization of a stream. Let us bring one into the code and demonstrate materialized values a little more:
val helloWorldStream: RunnableGraph[(UniqueKillSwitch, Future[Done])] =
Source.single("Hello world")
.map(s => s.toUpperCase())
.viaMat(KillSwitches.single)(Keep.right)
.toMat(Sink.foreach(println))(Keep.both)
val (killSwitch, doneF): (UniqueKillSwitch, Future[Done]) =
helloWorldStream.run()
killSwitch.shutdown()
// or
killSwitch.abort(new Exception("Exception from KillSwitch"))
The new thing here is viaMat, a full version of via (in the same way as toMat is a full version of to), which gives more control of materialized values. Another stage we added is KillSwitches.single, which just creates a kill switch per materialization (not shared between materializations) as its materialized values. We use Keep.right to preserve it and pass downstream, and Keep.both to preserve both KillSwitch and Future[Done].
The documentation has a good illustration for this:

Back-pressure
In real-world systems, it is not uncommon that a producer of data is faster than a consumer at some point of the data processing pipeline. In this case, there are several ways to deal with this. First, we can buffer incoming data on the consumer side, but this leads to memory consumption problems (including out-of-memory errors) if the consumer is consistently slower and the data is big enough. Second, we can drop messages on the consumer side, which, of course, is not always acceptable.
There is a technique called back pressure where the idea is to basically provide a mechanism for consumers to signal to producers how much data they can accept at the present moment. This might be done in the form of NACK, negative acknowledgement (when the consumer denies receiving a piece of data and signals this to the producer), or in the form of requests (when the consumer explicitly tells the producer how much data it is ready to accept). Akka Streams adheres to the second option.
Users of Akka Streams rarely see back pressure mechanics. However, you can explicitly control it while implementing your own stages. For instance, if a source is made of an actor, the actor will receive Request(n: Long) messages, which means “I am ready to receive n more elements”.
Here is an illustration of this:

The producer had previously accumulated the consumer’s demand of 2. It has just sent one message, so the demand decreased from 2 to 1. Meanwhile, the consumer has sent a request for another 3 messages. The consumer’s demand accumulated in the producer and will increase by 3 when the request arrives.
Akka Streams are back-pressured by default, but it is possible to alter this behaviour. For example, we can add a fixed size buffer with different strategies:
stream.buffer(100, OverflowStrategy.dropTail)
In this case, up to 100 elements will be collected, and on the arrival of 101, the youngest element will be dropped. There are some more strategies: dropHead (like dropTail but drops the oldest element), dropBuffer (drop the whole buffer), dropNew (drop the element that just came), backpressure (normal back pressure), fail (fails the stream).
Practical example
I have been using Akka Streams quite intensively over the last few months. One of the tasks was to consume events from Nakadi (a RESTful API to a distributed Kafka-like event bus), store them in AWS DynamoDB, send them to AWS SQS, and save a just-processed event offset in DynamoDB as well.
Events must be processed sequentially but only within one stage (e.g. an older event cannot be written to the database after a newer one), due to two reasons:
- The system is idempotent, one event can be processed multiple times with no harm (not good, as it is a waste of resources);
- Newer events have a higher priority than older ones.
Nakadi provides a RESTful API, i.e. can be used through HTTP. It responds with an infinite HTTP response with one event batch in JSON format per line (application/stream+json).
Akka HTTP — another part of Akka — is tightly integrated with Akka Streams. It uses Akka Streams for sending and processing HTTP requests.
Let us see the code (very simplified):
val http = Http(actorSystem)
val nakadiConnectionFlow = http.outgoingConnectionHttps(
nakadiSource.uri.getHost, nakadiSource.uri.getPort)
val eventBatchSource: Source[EventBatch, NotUsed] =
// The stream start with a single request object ...
Source.single(HttpRequest(HttpMethods.GET, uri, headers))
// ... that goes through a connection (i.e. is sent to the server)
.via(nakadiConnectionFlow)
.flatMapConcat {
case response @ HttpResponse(StatusCodes.OK, _, _, _) =>
response.entity.dataBytes
// Decompress deflate-compressed bytes.
.via(Deflate.decoderFlow)
// Coalesce chunks into a line.
.via(Framing.delimiter(ByteString("\n"), Int.MaxValue))
// Deserialize JSON.
.map(bs => Json.read[EventBatch](bs.utf8String))
// process erroneous responses
}
This Source presents an infinite (normally it should not finish) stream of events represented as the EventBatch case class. Then we pass these event batches through several stages:
eventBatchSource
.via(metricsStart)
.via(dataWriteStage)
.via(signalStage)
.via(offsetWriteStage)
.via(metricsFinish)
.viaMat(KillSwitches.single)(Keep.right)
.toMat(Sink.ignore)(Keep.both)
All of them are of type Flow[EventBatch, EventBatch, NotUsed]. Let us look at dataWriteStep, which might be worth noting:
val dataWriteStage: FlowType = Flow[EventBatch].map { batch =>
dynamoDBEventsWriter.write(batch)
batch
}.addAttributes(ActorAttributes.dispatcher("dynamo-db-dispatcher"))
.async
What is interesting here is that dynamoDBEventsWriter is only a tiny wrapper around Amazon’s DynamoDB driver for Java, which blocks I/O. We do not want to block in our data processing pipeline (otherwise, there’s no HTTP I/O or anything else while writing to DynamoDB). This is why this stage is made asynchronous (.async) and attached to a specific Akka dispatcher, dedicated to blocking I/O operations with DynamoDB. The other stages are pretty much the same. You can find more information about asynchronous stages in the documentation ( here and here), and in the Threading and Concurrency in Akka Streams Explained (Part I) blog post.
Basically, processing of events amounts to the materialization of this stream. Naturally, in the real production application this is more complex due to configurability of the pipeline itself – the code also includes monitoring, error recovery, etc.
The interesting moment here is that TCP/IP protocol itself is inherently back-pressured. Akka HTTP just makes a bridge between the low-level TCP/IP back pressure mechanism (TCP windows and buffers level) and the high-level Akka Streams back pressure. So, the whole stream that stretches over the network is back-pressured: if, say, signalStage is very slow and cannot keep up, we will not have the memory overflowed with the data incoming by HTTP.
GraphDSL
So far, we have considered only simple linear streams. However, Akka Streams supports so-called GraphDSL, needed to build graphs of an arbitrary complex structure. I will not go into this topic deeply, but just show an example of such a graph:

This graph is created by the following code:
import GraphDSL.Implicits._
RunnableGraph.fromGraph(GraphDSL.create() { implicit builder =>
val A: Outlet[Int] = builder.add(Source.single(0)).out
val B: UniformFanOutShape[Int, Int] = builder.add(Broadcast[Int](2))
val C: UniformFanInShape[Int, Int] = builder.add(Merge[Int](2))
val D: FlowShape[Int, Int] = builder.add(Flow[Int].map(_ + 1))
val E: UniformFanOutShape[Int, Int] = builder.add(Balance[Int](2))
val F: UniformFanInShape[Int, Int] = builder.add(Merge[Int](2))
val G: Inlet[Any] = builder.add(Sink.foreach(println)).in
C <~ F
A ~> B ~> C ~> F
B ~> D ~> E ~> F
E ~> G
ClosedShape
})
For more of the details you can consult the documentation here and here (where the illustration is taken from).
Custom stages and integration with Akka actors
Despite the abundance of out-of-the box processing stages in Akka Streams, it is not impossible or uncommon to write your own. The topic is quite broad, so not fitting to go into in this article. You can check out this post on the Akka blog for a better idea. It gives pretty good explanation of creating custom stages. Also make sure you take a look at the custom stream processing page in the documentation.
I wanted to show how easily Akka Streams and actors integrate. Consider the situation when we want to make an actor produce values for a stream, i.e. to be a Source. The first way is to call Source.actorRef that materializes to an actor, which sends downstream all messages sent to it. Another option is Source.actorPublisher, which receives Props of an actor, then implements ActorPublisher[T] trait, like this simple counter:
class LongCounter extends ActorPublisher[Long] {
private var counter = 0L
override def receive: Receive = {
case ActorPublisherMessage.Request(n) =>
for (_ <- 0 to n) {
counter += 1
onNext(counter)
}
case ActorPublisherMessage.Cancel =>
context.stop(self)
}
}
It is symmetrical for Sinks: we need to create an actor, which implements the ActorSubscriber trait:
class Printer extends ActorSubscriber {
override protected def requestStrategy: RequestStrategy =
WatermarkRequestStrategy(100)
override def receive: Receive = {
case ActorSubscriberMessage.OnNext(element) =>
println(element)
case ActorSubscriberMessage.OnError(throwable) =>
println(s"Failed with $throwable")
context.stop(self)
case ActorSubscriberMessage.OnComplete =>
println("Completed")
context.stop(self)
}
}
There are other possibilities, too – instead of creating a new actor, you can send messages to an existing one (with or without acknowledgements).
Summary and Links
In this article I have tried to cover the very basics of Akka Streams. This (and the whole field of asynchronous data processing pipelines) is a very big and interesting topic which you can delve into more at your own choosing.
Perhaps the biggest and most comprehensive guide is the official documentation, which I referred to throughout this post. Do not ignore the Akka blog, which is mostly about Streams. There are also plenty of conference videos online such as Akka Streams & Reactive Streams in Action by Konrad Malawski.
There are many other streaming libraries, and I must mention Reactive Extensions here. It is implemented for many platforms including JVM, .NET, Android, JavaScript, etc.
I am interested in the real-world applications of the library — and generally in asynchronous data processing pipelines. If you use any of this, drop me a line via Twitter at @ivan0yu.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Software Engineer!


