Sapphire Deep Learning Upskilling
Read about how our Dublin Tech Hub balances delivery with data science upskilling.

Data Scientist

Senior Data Scientist
At Zalando’s Fashion Insights Centre in Dublin, we work in autonomous data science delivery teams. This means that each team has the responsibility to deliver technology from research work and MVPs, through to production code and operational systems. This gives us a great opportunity to make decisions about how we organise our work so that we can balance the investment of effort in developing new data science solutions and necessary experimentation work, as well as production-ready code and maintenance of a live system.
For the last year, our team has been working on developing products that help derive insights from and make sense of unstructured web content, specifically focusing on the fashion domain. We primarily work with HTML data and text which necessitates the use of Natural Language Processing (NLP) and Machine Learning (ML). One of the challenges we face is keeping up with the state of the art and balancing delivery with data science upskilling.
Deep Learning For Natural Language Processing (NLP)
As a data science delivery team with core expertise in NLP, an area that we had been tracking was the application of deep learning in NLP. Deep learning is having a transformative impact in many areas where machine learning has been applied. The most early mature adoption has happened in areas where unstructured content can be more accurately classified or labelled for tasks such as speech recognition and image classification. One of the reasons for the success in these areas has been the ability of deep nets to learn an optimum features space and reduce time spent on the dark art of feature engineering.
In previous years, NLP was somewhat behind other fields in terms of adopting deep learning for applications. Text does not have a spatial feature space suitable for convolutional nets, nor is it entirely unstructured as it is already encoded via commonly understood vocabulary, syntax and grammar rules and other conventions. However, this has changed over the last few years, thanks to the use of RNNs, specifically LSTMs, as well as word embeddings. There are distinct areas in which deep learning can be beneficial for NLP tasks, such as in named entity recognition, machine translation and language modelling, just to name a few.
Upskilling Considerations in Data Science Delivery
In early August, one of our colleagues attended the Association for Computational Linguistics (ACL) conference in Berlin to better understand the benefits and readiness for adoption of deep learning in our team. As data scientists who have all spent time in academia, it is great to work in a company that not only allows you, but encourages and sponsors you to attend to conferences to keep up to date with the latest research approaches and technologies. When our colleague returned, he confirmed what we already knew: deep learning has become the state of the art for many NLP tasks, including one we are particularly interested in, Named Entity Recognition (NER).
At Zalando, we strive for excellence, and as researchers, we want to keep up with the state of the art. If our results could be better by using deep learning, we should test it, and if successful, adopt it. However, there was one initial obstacle: even if we had previous knowledge, none of us were experts in deep learning.
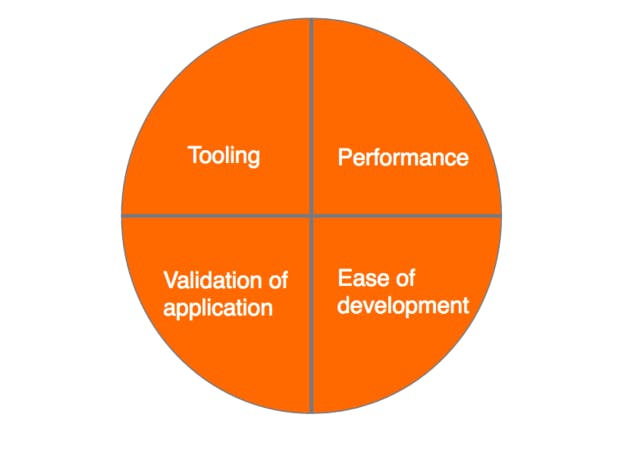
Contrary to academia, in a delivery team we have to take into account some considerations aside from the state of the art, such as:
- Tooling: Mature libraries with an active developer community, significant adoption, ideally backing from companies or open source
- Performance: Scaled and tried in production
- Ease-of-development: Cost/time-effective to bring from problem-setting to evaluation to deployment
- Validation of application: Has this approach demonstrated sufficient improvements over longer-established baseline systems? These benefits might include accuracy, ease of maintenance, or time to delivery
The Upskilling Plan
One of the challenges facing autonomous teams is making decisions to determine the what, how and when of invested time in upskilling. Upskilling is unanimously agreed to have a positive long-term effect for products and for an individual’s growth. However, spending time that could alternatively be spent on data science and engineering can often be a difficult pill to swallow, even guilt-inducing. We have a Tour of Mastery upheld as a core principle at Zalando, and a Practice Lead who through regular interaction and evaluation helps our team prioritize competencies to improve and source courses, training and other materials.
It looked like our roadmap for the quarter would contain some development of NLP models, improving the data quality of the initial systems we had developed previously. We wanted to dedicate time to better plan for this and communicate effectively with the product and delivery sides on what we felt was the best approach, as well as our capacity to do so. None of us had extensive experience in deep learning to date so we decided to sharpen the axe.
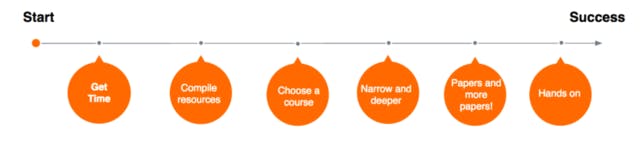
Get Time We ensured that guaranteed study time would be dedicated accordingly during our weekly planning. We chose three hours on Tuesday afternoons, approximately in the middle of our weekly cadence, for a period of six weeks. This was key, as otherwise the closest task takes your attention, and less urgent tasks get long-fingered. As well as communicating with each other, we also made sure that product stakeholders and leads were all aware of and understood the benefits of this initiative, and how it contributes to our capability to deliver state of the art data science.
We used this group as a way of collecting common thoughts about papers we were reading, compare practical exercises and engaging in knowledge sharing on mutually interesting. Even beyond the initial six weeks, we’ve still been using this slot to catch up on papers or articles we have read during the week.
Compile Resources We compiled a large list of courses, tutorials and of course (lots of!) papers. Taking the time to compile these resources means we have now built a repository of knowledge that will help anyone in the company wanting to upskill in deep learning for NLP.
Choose a Course We aimed to choose a course that balanced theoretical and practical understanding, eventually choosing Deep Learning by Google, in Udacity. We felt it balanced coverage and depth, theoretical and hands-on. It also included lessons on word embeddings and sequential learning (RNNs, LSTM). The videos are quite quick (if there is one complaint, it is that they are a bit too shallow), but they give you the basic intuition required to start doing your own research.
The best thing about the course without any doubt was the practical exercises using TensorFlow, which is a deep learning, open source library by Google. It is gaining popularity since it provides better support for distributed systems than Theano. Moreover, the documentation is very good, and once you get used to the structuring and how it works, it is easy to architect your own neural nets and design and execute your own experiments.
Narrow and deeper As we mentioned before, we are a team working intensively with NLP, so we focused quite a lot on NLP resources as well. Therefore, in parallel, we also started following the NLP Stanford classes, which are very complete and useful, and quite enjoyable since they provide an in depth mathematical and applications background for deep learning in NLP. We totally recommend it! Also very interesting, you can read this tutorial by Socher or check the Stanford NLP materials.
Read papers, papers, and more papers! What is the current research consensus? What are our reference papers? What is the best approach for our problem? During this entire process we read a long list of interesting papers on Deep Learning in general, and also focused on NLP (more here, also on recurrent neural network based language models, or distributed representations of words, phrases and their compositionality). On the NLP side, we focused on word embeddings and RNNs (some interesting resources in this public knowledge repo). Reading classic and state of the art papers is a key part of our jobs, since data scientists need to be up to date on the latest practices in our domain. We ultimately converged on several papers that we would use as reference papers and developed a consensus amongst ourselves on tools and state of the art approaches.
Get hands on This step is very important: get dirty and play with code. There is plenty of public domain code, models and data with which you can get started. Try to solve different problems with different architectures and you’ll see that it helps give you a better understanding and intuition of how to develop your own deep nets, and also about your approach to tuning those networks.
What We Learned
We found our approach to be far more preferable than ad-hoc reading or randomly playing with a library. Forming the theoretical knowledge, the intuitive understanding and ability to apply what we’ve learned are all key to solving new data science problems on the front line of delivery. It separates the effective data scientists from the rest.
In summary, our learnings from our upskilling planning would be to plan in advance for the quarter, carefully select the resources you will use to upskill, commit regular time, and be enthusiastic about learning. This has been a success for our team, and has left us ready to apply all of our theoretical and practical knowledge for the quarter to come. If you’d like some more information about how this approach can benefit your own data science team, reach out to us via Twitter at @PeleteiroAna or @adambermingham.




