What is Hardcore Data Science – In Practice?
Originally a research topic, data science has proven to add real business value for Zalando.

Delivery Lead – Recommendation and Search
This article originally appeared onoreilly.com.
Data science has become widely accepted across a broad range of industries in the past few years. Originally more of a research topic, data science has early roots in scientists efforts to understand human intelligence and create artificial intelligence; it has since proven that it can add real business value.
This is true for Zalando, Europe’s leading online fashion platform, where data science is heavily used to provide data-driven recommendations, among other things. Recommendations are provided as a backend service in many places, including product pages, catalogue pages, newsletters, and for retargeting.

Computing recommendations
Naturally, there are many ways to compute data-driven recommendations. For so-called collaborative filtering, user actions like product views, actions on a wishlist, and purchases, are collected over the whole user base and then crunched to determine which items have similar user patterns. The beauty of this approach lies in the fact that the computer does not have to understand the items at all; the downside is that one has to have a lot of traffic to accumulate enough information about the items. Another approach only looks at the attributes of the items, for example, recommending other items from the same brand, or with similar colors. And of course, there are many ways to extend or combine these approaches.

Simpler methods consist of little more than counting to compute recommendations, but of course, there is practically no limit to the complexity of such methods. For example, for personalized recommendations, we have been working with learning to rank methods that learn individual rankings over item sets. The above figure shows the cost function to optimize here, mostly to illustrate the level of complexity data science sometimes brings with it. The function itself uses a pairwise weighted ranking metric, with regularization terms. While being very mathematically precise, it is also very abstract. This approach can be used not only for recommendations in an fashion setting, but for all kinds of ranking problems, provided one has reasonable features.
Bringing mathematical approaches into industry
So, what does it take to bring a quite formal and mathematical approach, like what we’ve described above, into production? And what does the interface between data science and engineering look like? What kind of organizational and team structures are best suited for this approach? These are all very relevant and reasonable questions, because they decide whether the investment in a data scientist or a whole team of data scientists will ultimately pay off.
In the remainder of this article, I will discuss a few of these aspects, based on my personal experience of having worked as a machine learning researcher as well as having led teams of data scientists and engineers at Zalando.
Understanding data science versus production
Let’s start by having a look at data science and back-end production systems, and see what it takes to integrate these two systems.

The typical data science workflow looks like this: the first step is always identifying the problem and then gathering some data, which might come from a database or production logs. Depending on the data-readiness of your organization, this might already prove very difficult because you might have to first figure out who can give you access to the data, and then figure out who can give you the green light to actually get the data. Once the data is available, it’s preprocessed to extract features, which are hopefully informative for the task to be solved. These features are fed to the learning algorithm, and the resulting model is evaluated on test data to get an estimate of how well it will work on future data.
This pipeline is usually done in a one-off fashion, often with the data scientist manually going through the individual steps, using a programming language like Python, that comes with many libraries for data analysis and visualization. Depending on the size of the data, one may also use systems like Spark or Hadoop, but often the data scientist will start with a subset of the data first.
Why start small?
The main reason for starting small is that this is a process that is not done just once, but will in fact be iterated many times. Data science projects are intrinsically exploratory, and to some amount, open ended. The goal might be clear, but what data is available, or whether the available data is fit for the task at hand, is often unclear from the beginning. After all, choosing machine learning as an approach already means that one cannot simply write a program to solve the problem. Instead, one resorts to a data-driven approach.
This means that this pipeline is iterated and improved many times, trying out different features, different forms of preprocessing, different learning methods, or maybe even going back to the source and trying to add more data sources.
The whole process is inherently iterative, and often highly explorative. Once the performance looks good, one is ready to try the method on real data. This brings us to production systems.

Distinguishing a production system from data science
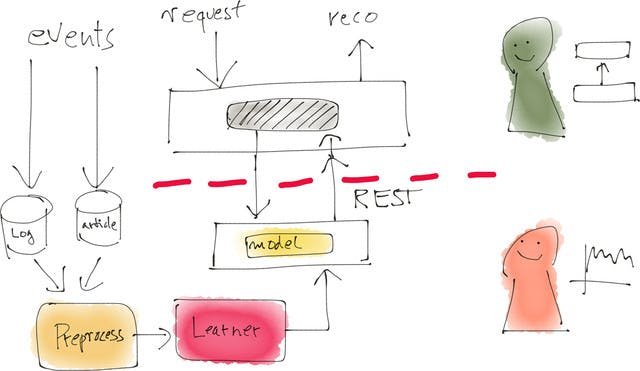
Probably the main difference between production systems and data science systems is that production systems are real-time systems that are continuously running. Data must be processed and models must be updated. The incoming events are also usually used for computing of key performance indicators like click-through rates. The models are often retrained on available data every few hours and then loaded into the production system that serve the data via a REST interface, for example.
These systems are often written in programming languages like Java for performance and stability reasons.

If we put these two systems side-by-side, we get a picture like the Figure above. On the top right, there is the data science side, characterized by using languages like Python, or systems like Spark, but often with one-shot, manually-triggered computations, and iterations to optimize the system. The outcome of that is a model, which is essentially a bunch of numbers that describe the learned model. This model is then loaded by the production system. The production system is a more classical enterprise system, written in a language like Java, which is continually running.
The picture is a bit simplifying, of course. In reality, models have to be retrained, so that some version of the processing pipeline must also be put into place on the production side to update the model every now and then.
Note that the A/B testing, which happens in the live system, mirrors the evaluation in the data science side. These are often not exactly comparable because it is hard to simulate the effect of a recommendation, for example, offline, without actually showing it to customers, but there should be a link in performance increase.
Finally, it’s important to note that this whole system is not “done” once it is set up. Just as one first needs to iterate and refine the data analysis pipeline on the data science side, the whole live system also needs to be iterated as data distributions change, and new possibilities for data analysis open up. To me, this "outer iteration" is the biggest challenge to get right—and also the most important one, because it will determine whether you can continually improve the system and secure your initial investment in data science.
Data scientists and developers: modes of collaboration
So far, we have focused on how systems typically look in production. There are variations in how far you want to go to make the production system really robust and efficient. Sometimes, it may suffice to directly deploy a model in Python, but the separation between the exploratory part and production part is usually there.
One of the big challenges you will face is how to organize the collaboration between data scientists and developers. “Data scientist” is still a somewhat new role, but the work they have to do differs enough from those of typical developers that you should expect some misunderstandings and difficulties in communication.
The work of data scientists is usually highly exploratory. Data science projects often start with a vague goal and some ideas of what kind of data is available and methods that could be used, but very often, you have to try out ideas and get insights into your data. Data scientists write a lot of code, but much of this code is there to test out ideas and is expected to not be part of the end solution.

Developers, on the other hand, naturally have a much higher focus on coding. It is their goal to write a system, to build a program that has the required functionality. Developers sometimes also work in an exploratory fashion, building prototypes, proof of concepts, or performing benchmarks, but the main goal of their work is to write code.
These differences are also very apparent in the way the code evolves over time. Developers usually try to stick to a very clearly defined process that involves creating branches for independent work streams, then having those reviewed and merged back into the main branch. People can work in parallel, but need to incorporate approved merges into the main branch back into their branch, and so on. It is a whole process around making sure that the main branch evolves in an orderly fashion.

While data scientists also write a lot of code, as I mentioned, it often serves to explore and try out ideas. So, you might come up with a version 1, which didn’t quite do what you expected, then you have a version 2 that leads to versions 2.1 and 2.2 before you stop working on this approach, and go to versions 3 and 3.1. At this point you realize that if you take some ideas from 2.1 and 3.1 you can actually get a better solution, leading to versions 3.3 and 3.4, which is the optimal solution.

The interesting thing is that you would actually want to keep all those dead ends because you might need them at some later point. You might also put some of the things that worked well back into a growing toolbox, something like your own private machine learning library, over time. While developers are interested in removing “dead code“ (also because they know that you can always retrieve that later on, and they know how to do that quickly), data scientists often like to keep code, just in case.
Both of these differences mean, in practice, that the collaboration between developers and data scientists is often challenging. Standard software engineering practices don’t really work out for data scientist’s exploratory work mode because the goals are different. Introducing code reviews and an orderly branch, review, and merge back workflow would just not work for data scientists and slow them down. Likewise, applying this exploratory mode to production systems also won’t work.
So, how can we structure the collaboration to be most productive for both sides? A first reaction might be to keep the teams separate—for example, by completely separating the codebases and having data scientists work independently, producing a specification document as outcome that then needs to be implemented by the developers. This approach works, but it is also very slow and error prone because reimplementing may introduce errors, especially if the developers are not familiar with data analysis algorithms, and performing the outer iterations to improve the overall system depends on developers having enough capacity to implement the data scientists specifications.

Luckily, many data scientists are actually interested in becoming better software engineers, and the other way round, so we have started to experiment with modes of collaboration that are a bit more direct and help to speed up the process.
For example, data science and developer code bases could still be separate, but there is a part of the production system that has a clearly identified interface into which the data scientists can hook their methods. The code that communicates with the production system obviously needs to follow stricter software development practices, but would still be in the responsibility of the data scientists. That way, they can quickly iterate internally, but also with the production system.
One concrete realization of that architecture pattern is to take a microservice approach and have the ability in the production system to query a microservice owned by the data scientists for recommendations. That way, the whole pipeline used in the data scientist’s offline analysis can be repurposed to also perform A/B tests or even go in production without developers having to reimplement everything. This also puts more emphasis on the software engineering skills of the data scientists, but we are increasingly seeing more people with that skill set. In fact, we have lately changed the title of data scientists at Zalando to “research engineer (data science)” to reflect the fact.
With an approach like this, data scientists can move fast, iterate on offline data, iterate in a production setting, and the whole team can migrate stable data analysis solutions into the production system over time.
Constantly adapt and improve
So, I’ve outlined the typical anatomy of an architecture to bring data science into production. The key concept to understand is that such a system needs to constantly adapt and improve (as almost all data-driven projects working with live data). Being able to iterate quickly, trying out new methods, and testing the results on live data in A/B-tests is most important.
In my experience, this cannot be achieved by keeping data scientists and developers separate. At the same time, it’s important to acknowledge that their working modes are different because they follow different goals—data scientists are more exploratory and developers are more focused on building software and systems.
By allowing both sides to work in a fashion that best suits these goals and defining a clear interface between them, it is possible to integrate the two sides so that new methods can be quickly tried out. This requires more software engineering skills from data scientists, or at least support by engineers who are able to bridge between both worlds.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Data Engineer!




