Linting and ESLint: Write Better Code
Why should you spend the time required to lint your code? Up your code quality game right here.

Software Engineer
Since joining Zalando, I have had the opportunity to dive into some open source projects like ESLint, a pluggable JavaScript linter. Here is my take on what ESLint is, a brief description of linting in general, and why it is so important.
What is linting?
Generally speaking, linting is a tool for static code analysis and therefore part of white-box testing. The main purpose of white-box testing is to analyse the internal structure of components or a system. To make sense of this, a developer would already have knowledge of the written code and will define rules or expectations about how a component should behave (unit tests), or how it should be structured (linting).
In modern web development, this describes the process (and tools) of applying rules against a codebase and flagging code structures that violate these rules. Rules can vary from code styling rules, so code appears to be written by one person, to much more complex rules (e.g. here). Even fixing these issues is part of modern JavaScript linting.
Why should you lint your code?
Linting code is already an established part of any (popular) JavaScript project and, in my opinion, has a lot of benefits such as:
- Readability
- Pre-code review
- Finding (syntax) errors before execution
As we have the possibility to define a set of styling rules, this increases the readability of our code towards the effort of having our codebase look like it was written by “one person”. This is important, as it can happen that software engineers move from codebase to codebase within projects meaning a lot of people become involved. A common set of rules makes it easier to really understand what the code is doing.
Further linting rules help to improve code reviews, as linting already acts as a pre-code review, checking against all the basic issues such as syntax errors, incorrect naming, the tab vs. spaces debate, etc. It increases the value of having code reviews, as people are then more willing to check the implementation rather than complain about syntax errors.
ESLint in a nutshell
ESLint is an open source, JavaScript linting utility originally created by Nicholas C. Zakas. Code linting is a type of static analysis that is frequently used to find problematic patterns or code that doesn’t adhere to certain style guidelines. There are code linters for most programming languages, and compilers can sometimes incorporate linting into the compilation process.
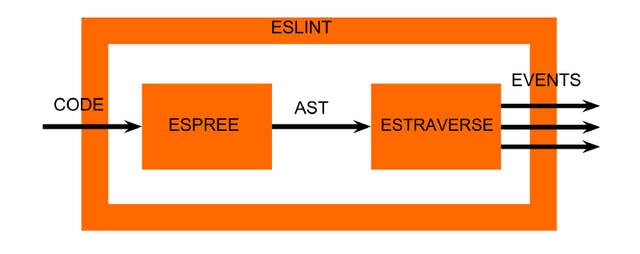
ESLint is a CLI tool which is wrapped around two other open source projects. One is Espree, which creates an Abstract Syntax Tree (AST) from JavaScript code. Based on this, AST ESLint uses another project called Estraverse which provides traversal functions for an AST. During the traversal, ESLint emits an event for each visited node where the node type is the Event name, e.g. FunctionExpression or WithStatement. ESLint rules are therefore just functions subscribing to node types it wants to check.
It is also important to note that ESLint doesn’t support new language features until they reach Stage 4 of the proposal process of TC39.
For further explanation, I will use the following simple script which generates an AST for the given JavaScript code.
var espree = require('espree');
var fs = require('fs');
var code = `let array = [1,2,'b'];
`;
var ast = espree.parse(code, {
ecmaVersion: 6
});
console.log("writing ast to ast.json")
fs.writeFile("ast.json", JSON.stringify(ast, null, 4), function(err) {
if(err) return err;
});
Abstract Syntax Tree
The AST is an abstract representation of your code structure. In the JavaScript world, this abstract representation is defined by the ESTree project and is the starting point if you want to understand JavaScript AST’s or want to build / extend on your own. I highly recommend reading the ES5 AST grammar documentation, as it helps to understand the different types of nodes represented in the AST.
A specific point of difference with the AST is that each node describes a specific grammar definition in your code, as you can see below – our one line of JavaScript code already produces an AST with 5 nodes, and each node itself contains additional information which you can see in the JSON representation below. This graph representation is just one example of how a Tree representation of our code might look like (I would also interpret the values in ArrayExpression as individual nodes, but developers are free to choose themselves).
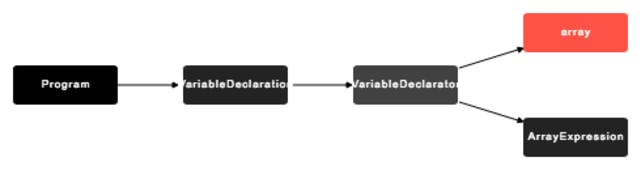
Visualizing our AST (with http://resources.jointjs.com/demos/javascript-ast)
As you can see, the AST of just one line of code and a simple Tree representation contains a lot of information.
{
"type": "Program",
"start": 0,
"end": 23,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 22,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 21,
"id": {
"type": "Identifier",
"start": 4,
"end": 9,
"name": "array"
},
"init": {
"type": "ArrayExpression",
"start": 12,
"end": 21,
"elements": [
{
"type": "Literal",
"start": 13,
"end": 14,
"value": 1,
"raw": "1"
},
{
"type": "Literal",
"start": 15,
"end": 16,
"value": 2,
"raw": "2"
},
{
"type": "Literal",
"start": 17,
"end": 20,
"value": "b",
"raw": "'b'"
}
]
}
}
],
"kind": "let"
}
],
"sourceType": "script"
}
What kind of information do we find in the AST?
As previously mentioned, one line of JavaScript code contains a vast amount of information for an AST. Every entry in the AST is a Node object, consisting of a ‘type’ property and a SourceLocation Object.
The type property is a string representing the different Node variants in the AST. The SourceLocation Object consists of a start and end property. The type, start, and end line number provide us with information about the structure of our code. Generally, a JavaScript AST consists of Statements, Expressions and Declarations (for ES5), which doesn’t sound like much, but have a lot of variations. For those interested in ES2016 and beyond, see the following:
Traversing the AST
Now that we have generated our AST for our JavaScript code, what can we do next? Traversing! As great as the AST is, the exciting part starts with traversing it and analysing the information it has. For traversing the AST, ESLint relies on the Estraverse project which traverses over the generated AST (from Espree).
Estraverse provides a traverse functionality which executes a given statement. In this traverse function we can subscribe to specific types of nodes and complete our analysis. For example, if we want to make sure that all Literal Definitions in our Array declaration are Integers, we could check for that with the sample script below:
var estraverse = require('estraverse');
var fs = require('fs');
fs.readFile('./ast.json', 'utf-8', function(err, ast) {
if(err) throw err;
const data = JSON.parse(ast);
estraverse.traverse(data, {
enter: function(node, parent) {
if(node.type === "Literal" && parent.type === "ArrayExpression") {
if(!Number.isInteger(node.value)){
// stop traversal when a Literal is not a number
return estraverse.VisitorOption.Break;
}
}
},
leave: function(node, parent) {
//nothing for now
}
});
});
Furthermore, the traverse functionality of Estraverse uses the Visitor design pattern, which allows us to execute functions for each visited node of the AST instead of traversing the whole AST and performing operations afterwards. By debugging the traverse function of Estraverse, it has showed that it is using the depth-first algorithm of traversing a Tree. This means Estraverse is traversing to the end of a child node (depth-first) before it begins backtracking. The Visitor pattern, combined with a depth-first search, then allows ESLint to trigger Events whenever it enters an AST node or leaves it immediately.
Plugins
The architecture of ESLint is pluggable, so if you want to create new rules for specific problems, frameworks, or use cases you have, it is recommended to develop ESLint plugins rather opening up an issue and requesting changes. This presents quite a powerful opportunity to create much more complex code analysis than ESLint can provide. Therefore, developers should consider creating plugins as they are npm modules.
Thanks to the pluggable architecture, it is easy to use already existing plugins or rules for different frameworks, libraries, or companies, e.g. eslint-plugin-react, eslint-plugin-vue or eslint-contrib-airbnb.
Wrap-Up
While we all might use ESLint and linting tools in our JavaScript projects, we don’t know much about the insights of these projects and the challenges behind them, or how they provide us with the tools to create good quality code. I highly recommend every JavaScript developer play around with these tools, as this is still a topic only a select few really work on, but are actually used everywhere. A few projects doing similar work are: Prettier, babel-eslint, and The Flow Parser.
As a next step, I’d like to create a small ESLint plugin tutorial for interested developers to see how they can create their own custom ruleset for different use cases, e.g. placing rules into the core of ESLint. If you have any suggestions or ideas for a ESLint plugin you’d like to see, grab me on Twitter at @Fokusman.





