Rock Solid Kafka and ZooKeeper Ops on AWS
Reducing ops effort while maintaining Kafka and Zookeeper

Software Engineer
Reducing ops effort while maintaining Kafka and Zookeeper
This post is targeted to those looking for ways to reduce ops effort while maintaining Kafka and Zookeeper deployments on AWS and also improving their availability and stability. In a nutshell, we are going to explain how using Elastic Network Interfaces can improve over a straight out of the box setup.
We will examine how Kafka and Zookeeper react to instance terminations and their subsequent replacement by newly launched instances.
For this example, we'll consider Zookeeper to have been deployed with Exhibitor, which is a popular choice since it facilitates instance discovery and automatic ensemble formation by sharing configurations over S3 buckets. For simplicity we're considering a three instances setup, but in real life, five instances would be recommended.
The picture below shows the initial state of our cluster.
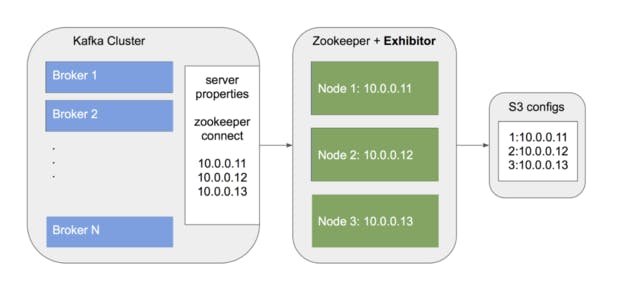
As we can see in the image, each Zookeeper instance gets to know about each other through a self advertised IP addresses on the S3 bucket. As for Kafka, it gets to know about Zookeeper instances through the zookeeper.connect' property provided to each broker.
Is it safe to terminate a single Zookeeper instance?
Let's examine what happens when AWS terminates one Zookeeper instance.

See the following actions:
- Zookeeper keeps serving, since the Quorum condition is preserved with two out of three instances still available.
- All Kafka connections served by the terminated instance are closed and automatically re-opened on both of the two remaining instances.
- When Kafka tries to open a connection on the terminated broker, it will fail but it will automatically try on the next one in the list.
Summarising, even though the system is missing one instance from the original composition, everything keeps working as expected.
- If you use Exhibitor's instance add/removal feature, be aware that Exhibitor might automatically remove the terminated instance from the S3 configuration causing a rolling restart of the remaining two exhibitors, which on its turn could cause instability in the ensemble and some moments of downtime.
Does it recover without any human interaction?
One common technique to automatically replace terminated instances in AWS is to use Auto Scaling Groups with fixed number of instances. There are other techniques, like Amazon EC2 Auto Recovery, which is more interesting but is not available for all types of instances.
In case of Auto Scaling Groups, a new instance is launched as a reaction to the remaining number of instances (two) not matching the minimum desired number (three). The newly launched instance would have a different IP address. This is a very important detail. Having a different IP address will require a lot of work to restore the initial state of the cluster.
- Exhibitor includes the new IP address in the nodes list configuration.
- All Zookeeper instances are restarted in order to reload the new configuration and accept the new instance in the ensemble.
- Kafka configuration ‘zookeeper.connect’ needs to be updated with the new Zookeeper IP address and all Kafka instances restarted in order to reload this configuration.
Considering all these restarts are done one by one, depending on the number of Kafka instances in the cluster, it could take hours.
Restarting Kafka takes time:
- Kafka needs to be gracefully stopped, not to corrupt the indexes, which would require even more time to launch the process again.
- Some publishing requests might fail since it takes some time for producers to find out that those partitions are no longer served by that broker. It means instability and failures for clients performing synchronous tasks.
- All the data ingested by the other replicas while the broker is down would have to be copied, which takes several minutes depending on the load.
- Leadership needs to be switched back to the broker after restart, in order to preserve a well-balanced load on the cluster. This process needs to be closely watched, because restarting the next broker before the previous came back and replicated all data would mean that some partitions could go offline.
- Leadership switch again causes some moments of instability.
How to do it better
What if Kafka could reload ‘zookeeper.connect’ without restarts? Not an option, this feature is not available and discussions about implementing it are stuck since January of 2017.
What if we used domain names for ‘zookeeper.connect’ instead of IP addresses? Also not an option. Zookeeper client library resolves domain names only once.
What if we could have static IP addresses that don't change?
After some investigation, we came up with this idea of using Elastic Network Interfaces, which have a static IP address, and attaching them to instances.
This would avoid the need to update configurations and consequently, avoid restarting Kafka and Zookeeper.
How Elastic Network Interfaces work
- First we create a pool of Network Interfaces and tag them accordingly, so that Zookeeper instances are able to filter them later and automatically attach an available one. Be aware that Network Interfaces are bound to the subnet of a specific Availability Zone.
- Then we launch Zookeeper instances, which during initialization execute the following script to attach a Network Interface and configure it properly.
Let's go through the instance termination scenario we analyzed before, but this time with Network Interfaces and static IP addresses.
- Each Zookeeper node communicates through an attached Network Interface (white box)

- One Zookeeper instance is terminated, but the attached Network Interface is not.
- A new Zookeeper instance, with a different IP address is launched to replace the old one, but it still uses the same Elastic Network Interface, thus not changing the exposed IP address. This is very important, because it means that Kafka no longer needs to be restarted to reach the newly launched Zookeeper instance.

This technique helped us reduce the amount of time spent on operations and raised the bar in terms of stability and availability, which users of our Kafka cluster greatly appreciate.
Emacs 24.4.1 Org mode 8.2.10)
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Software Engineer!


