Many-to-Many Relationships Using Kafka
Real-time joins in event-driven microservices

Big Data Software Engineer
Real-time joins in event-driven microservices
As discussed in my previous blog post, Kafka is one of the key components of our event-driven microservice architecture in Zalando’s Smart Product Platform. We use it for sequencing events and building an aggregated view of data hierarchies. This post expands on what I previously wrote about the one-to-many data model and introduces more complex many-to-many relationships.
To recap: to ensure the ordering of all the related entities in our hierarchical data model (e.g. Media for Product and the Product itself) we always use the same partition key for all of them, so they end up sequenced in a single partition. This works well for a one-to-many relationship: Since there’s always a single “parent” for all the entities, we can always “go up” the hierarchy and eventually reach the topmost entity (“root” Product), whose ID we use to derive the correct partition key. For many-to-many relationships, however, it’s not so straightforward.
Let’s consider a simpler data model that only defines two entities: Products (e.g. Shoes, t-shirt) and Attributes (e.g. color, sole type, neck type, washing instructions, etc., with some extra information like translations). Products are the “core” entities we want to publish to external, downstream consumers and Attributes are meta-data used to describe them. Products can have multiple Attributes assigned to them by ID, and single Attributes may be shared by many Products. There’s no link to a Product in Attribute.
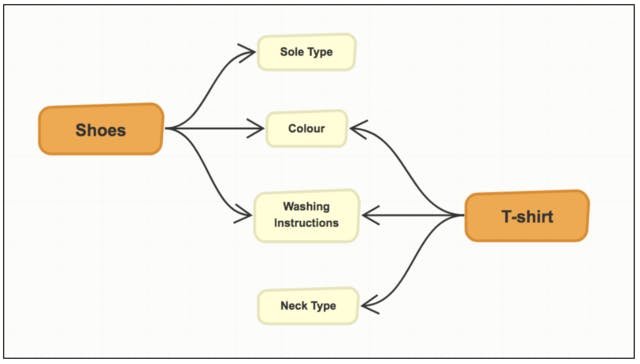
Given the event stream containing Product and Attribute events, the goal is to create an “aggregation” application, that consumes both event types: “resolves” the Attribute IDs in Product entities into full Attribute information required by the clients and sends these aggregated entities further down the stream. This assumes that Attributes are only available in the event stream, and calling the Attribute service API to expand IDs to full entities is not feasible for some reason (access control, performance, scalability, etc.).
Because Attributes are “meta data”, they don’t form a hierarchy with the Product entity; they don’t “belong” to them, they’re merely “associated” with them. It means that it’s impossible to define their “parent” or “root” entity and, therefore, there’s also no single partition key they could use to be “co-located” with the corresponding Products in a single partition. They must be in many (potentially: all) of them.
This is where Kafka API comes in handy! While Kafka is probably best known from its key-based partitioning capabilities (see: ProducerRecord(String topic, K key, V value) in Kafka’s Java API), it’s also possible to publish messages directly to the specific partition using the alternative, probably a less known ProducerRecord(String topic, Integer partition, K key, V value). This, on its own, allows us to broadcast an Attribute event to all the partitions in a given topic, but if we don’t want to hardcode the number of partitions in a topic, we need one more thing: producer’s ability to provide the list of partitions for a given topic using the partitionsFor method.
The complete Scala code snippet for broadcasting events could now look like this:
import scala.collection.JavaConverters._
Future.traverse(producer.partitionsFor(topic).asScala) { pInfo =>
val record = new ProducerRecord[String, String](topic, pInfo.partition, partitionKey, event)
// send the record
}
I intentionally didn’t include the code to send the record, because the Kafka’s Java client returns Java Future, so converting this response to Scala Future would require some extra code (i.e. using Promise), which could clutter this example. If you’re curious on how this could be done without the awful, blocking Future { javaFuture.get } or similar (please, don’t do this!), you can have a look at the code here.
This way we made the same Attribute available in all the partitions, for all the “aggregating” Kafka consumers in our application. Of course it carries consequences and there’s a bit more work required to complete our goal.
Because the relationship information is stored in Product only, we need to persist all the received Attributes somewhere, so when a new Product arrives, we can immediately expand the Attributes it uses (let’s call it “Attribute Local View”, to emphasise it’s a local copy of Attribute data, not a source of truth). Here is the tricky part: Because we’re now using multiple, parallel streams of Attribute data (partitions), we need an Attribute Local View per partition! The problem we’re trying to avoid here, which would occur in case of a single Attribute Local View, is overwriting the newer Attribute data coming from “fast” partition X, by older data coming from a “slow” partition Y. By storing Attributes per partition, each Kafka partition’s consumer will have access to its own, correct version of Attribute at any given time.
While storing Attributes per partition might be as simple as adding Kafka partition ID to the primary key in the table, it may cause two potential problems. First of all, storing multiple copies of the same data means – obviously – that the storage space requirements for the system are significantly raised. While this might not be a problem (in our case Attributes are really tiny comparing to the “core” entities), this is definitely something that has to be taken into account during capacity planning. In general, this technique is primarily useful for problems, where the broadcasted data set is small.
Secondly, by associating the specific versions of Attributes with partition IDs, the already difficult task of increasing numbers of partitions becomes even more challenging, as Kafka’s internal topic structure has now “leaked” to the database. However, we think that growing the number of partitions is already a big pain (breaking the ordering guarantees at the point where partitions were added!) that requires careful preparations and additional work (e.g. migrating to the new topic with more partitions, rather than adding partitions “in place” to the existing one), so it’s a tradeoff we accepted. Also, to reduce the risk of extra work we try to carefully estimate the number of partitions required for our topics and tend to overprovision a bit.
If what I just described sounds familiar to you, you might have been using this technique without even knowing what it is; it’s called broadcast join. It belongs to a wider category of so called map-side joins, and you can find different implementations of it in libraries like Spark or Kafka Streams. However, what makes this implementation significantly different is the fact that it reacts to the data changes in real-time. Events are broadcast as they arrive, and local views are updated accordingly. The updates to aggregations on product changes are instant as well.
Also, while this post assumes that only Product update may trigger entity aggregation, the real implementation we’re using is doing it on Attribute updates as well. While, in principle, it’s not a difficult thing to do (a mapping of Attribute-to-Product has to be maintained, as well as the local view of the last seen version of a Product), it requires significantly more storage space and carries some very interesting performance implications as single Attribute update may trigger an update for millions of Products. For that reason I decided to keep this topic out of the scope of this post.
As you just saw, you can handle many-to-many relationships in a event-driven architecture in a clean way using Kafka. You’ll benefit from not risking having outdated information and not resorting to direct service calls, which might be undesirable or even impossible in many cases. As usual, it comes at a price, but if you weigh pros and cons carefully upfront, you might be able to make a well-educated decision to your benefit.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Software Engineer!


