A Machine Learning Pipeline with Real-Time Inference
How we improved an ML legacy system using Amazon SageMaker

Applied Scientist

Senior Applied Scientist

Software Engineer

Senior Applied Scientist

Applied Science Manager
Customers love the freedom to try the clothes first and pay later. We’d love to offer everyone the convenience of deferred payment. However, fraudsters exploit this to acquire goods they never pay for. The better we know the probability of an order defaulting, the better we can steer the risk and offer the convenience of deferred payment to more customers.
That’s where our Machine Learning models come into play.
We have been tackling this problem for a while now. Everything started with a simple Python and scikit-learn setup. In 2015 we decided to migrate to Scala and Spark in order to scale better. You can read about this transition on our engineering blog. Last year we started to explore the potential value of tooling provided by Zalando's Machine Learning Platform (ML Platform) team as part of our strategy investment.
Pain Points with the existing solution
Our current solution serves us well. However, it has a few pain points, namely:
- It’s highly coupled to Scala and Spark which makes using state of the art libraries (mostly Python) difficult.
- It contains custom tailored code for functionalities which nowadays can be replaced by managed services. This adds an additional layer of complexity, making it difficult to maintain and to onboard new team members.
- It is a bit problematic in production: it uses a lot of memory, suffers from latency spikes, new instances start rather slowly which affects scalability.
- It has a monolithic design, meaning that feature preprocessing and model training are highly coupled. There is no pipeline with clear steps and everything runs on the same cluster during training.
Requirements for the New System
We started the project by writing down requirements for the new solution. The requirements fulfilled by our current system still stand:
- API: the new system needs to conform to the existing API. We receive a JSON response with order data, and return a response in a JSON format.
- Latency: the deployed service must respond to requests quickly. 99.9% of responses must be returned under a threshold in the order of milliseconds.
- Load: the busiest model must be able to handle hundreds of requests per second (RPS) on a regular basis. During sales events, the requests rate for a model may scale at a higher order of magnitude.
- Support for multiple models in production: several models, divided per assortment type, market, etc., must be available in the production service at any given time.
- Unified feature implementation: our model features require preprocessing (extraction from the request JSON) both in production and in our training data (which comes in the same JSON format). The preprocessing applied to incoming requests in production must be identical to that applied to the training data. We want to avoid implementing this logic twice for both cases.
- Performance metrics: we must be able to compare the performance between the new and the old version of a model (using the same data) to improve our tagging capabilities.
To alleviate the current pains, we require our new system to meet the following criteria in addition to those above:
- Independence from a specific model framework: our research team develops improved models with different frameworks, such as PyTorch, Tensorflow, XGBoost, etc.
- Fast scale-up: the production system should adjust to growing traffic and accept requests in a matter of minutes.
- Clear pipeline: the pipeline should have clear steps, especially the separation between data preprocessing and model training should be easy to understand.
- Use existing services: ML tooling made quite a leap in the recent years and when possible we should take advantage of what’s available instead of building custom solutions.
Architecture of the New System
The system is a machine learning workflow built primarily from services provided by AWS. At Zalando, we use a tool provided by Zalando’s ML Platform team called zflow. It is essentially a Python library built on top of AWS Step Functions, AWS Lambdas, Amazon SageMaker, and Databricks Spark, that allows users to easily orchestrate and schedule ML workflows.
With this approach we steer away from implementing the whole system from scratch, hopefully making it easier to understand, which was one of the pain points (#2) of our prior system.
In this new system, a single workflow orchestrates the following tasks:
- Training data preprocessing, using a Databricks cluster and a scikit-learn batch transform job on SageMaker
- Training a model using a SageMaker training job
- Generating predictions with another batch transform job
- Generating a report to demonstrate model’s performance, done with a Databricks job
- Deploying a SageMaker endpoint to serve the model

The platform solution allowed us to create a clean workflow with a lot of flexibility when it comes to technology selection for all the steps. We consider this a big improvement in regards to our pain point #4.
Using a SageMaker training job allows us to substitute the model training step with any model available as a SageMaker container. In rare cases, when the algorithm is not already provided, we still have the possibility to implement the container on our own. This gives us much more flexibility and deals with pain point #1 discussed before.
Model Evaluation
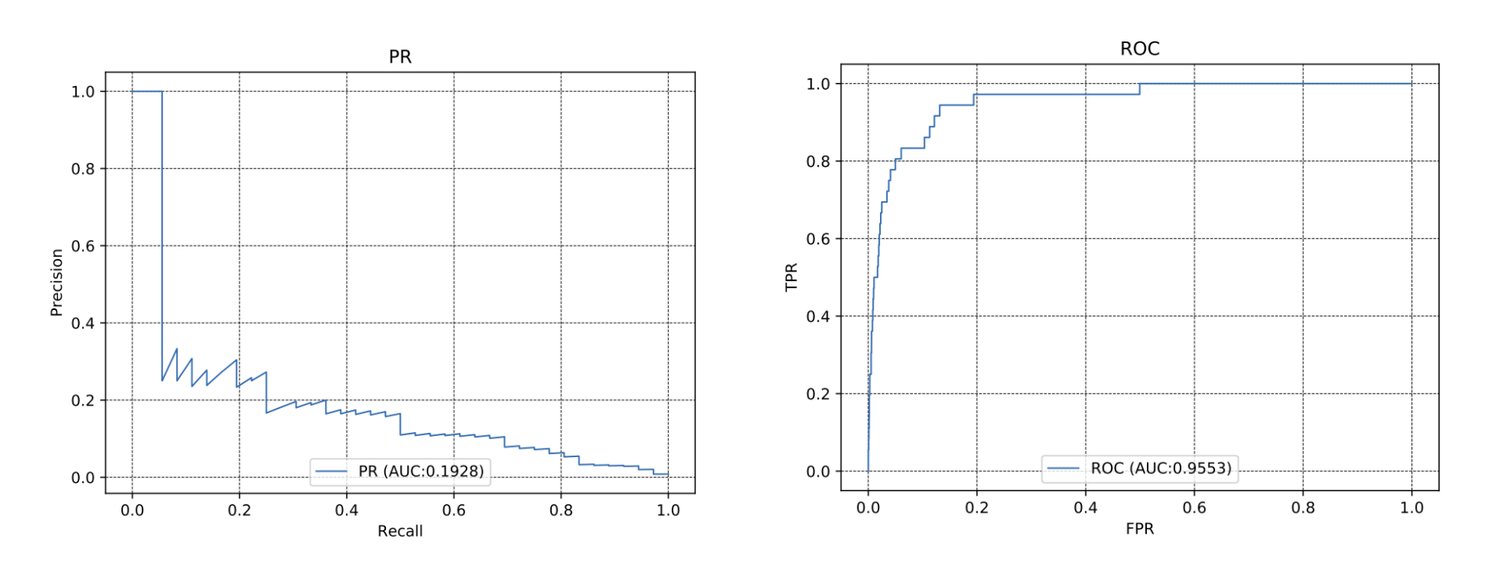
After the training is finished, a SageMaker model is generated. To evaluate the performance of the model candidate we perform inference on a dedicated test dataset. As we needed to check additional metrics to the ones provided out of the box by SageMaker, we added a custom Databricks job to calculate those metrics and to plot them in a PDF report (example below, where we see a model performing poorly).
Model Serving
At inference time, a SageMaker endpoint serves the model. Requests include a payload which requires preprocessing before it is delivered to the model. This can be accomplished using a so-called “inference pipeline model” in SageMaker.

The inference pipeline here consists of two Docker containers:
- A scikit-learn container for processing the incoming requests, i.e. extracting features from the input JSON or basic data transformations
- Main model container (i.e. XGBoost, PyTorch) for model predictions
The containers are lightweight and optimized for serving. They are able to scale-up sufficiently fast. This solved our pain point #3.
Performance Metrics
Latency and Success Rate
We then performed a series of load tests. During every load test the endpoint was hit continuously for 4 minutes. We varied:
- The EC2 instance type
- Number of instances
- The request rate. Different rates were applied to different AWS instance types. For example, it does not make sense to use ml.t2.medium instances to serve a model at a highest request rate, as they are not meant for such a load.
We reported the following metrics:
- Success: the percentage of all requests which returned an HTTP 200 OK status. 100% is optimal. Although there is no hard threshold here, the success rate should be high enough to serve endpoint requests.
- 99th: the 99th percentile for response rates of all requests, in milliseconds. To be usable, an endpoint must be able to respond to requests within the agreed sub-second threshold.
Sample results, for m5.large instance type:
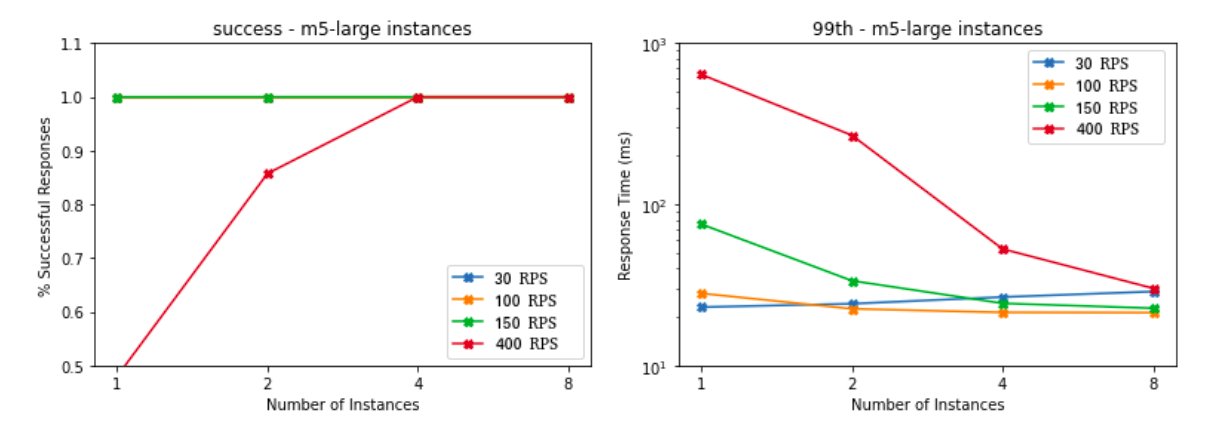
Some of our findings:
- For a rate of 200 requests/s, a single ml.m5.large instance can handle the load with a p99 of under 80ms.
- For a rate of 400 requests/s, the success rate is not near 100% until 4 or more ml.m5.large instances are used. The response rates are under 50ms.
- For the 1000 requests/s rate, 2 or more ml.m5.4xlarge or ml.m5.12xlarge instances can keep the success rate with response times below 200ms.
Cost
Based on our estimates the cost of serving our models will increase significantly after the migration. We anticipate the increase by up to 200%. The main reason behind it is cost efficiency of the legacy system, where all the models are served from one big instance (multiplied for scaling). In the new system every model gets a separate instance(s).
Still, this is a cost increase that we are willing to accept for the following reasons:
- Model flexibility. Having a separate instance per model means every model can use a different technology stack or framework for serving.
- Isolation. Every model’s traffic is separated, meaning we can scale each model individually, and flooding one model with requests doesn’t affect other models.
- Use of managed services instead of maintaining a custom solution.
Scale-up Time
We would like to be able to adjust our infrastructure to traffic as fast as possible. This is why we verified how much time it takes to scale the system up. Based on our experiments, adding an instance to a SageMaker endpoint with our current configuration reduces scale-up time by 50% over our old system. However, we wish to explore options for reducing this time further.
Cross Team Collaboration
Development of this system was a collaborative effort of two different teams: Zalando Payments and Zalando Machine Learning Platform, with each contributing members to a dedicated virtual team. This inter-team collaborative workstyle is typical for the ML Platform team, which offers the services of data scientists and software engineers to accelerate onboarding to the platform. To define the scope of the collaboration, the two teams created a Statement of Work (or SoW) to specify what services and resources the ML Platform will provide, and for what length of time. The entire collaboration lasted 9 months.
The two teams collaborated in a traditional Kanban development style: we developed user stories, broke them into tasks, and completed each task. We met weekly for a replanning and had daily standups to catch up.
Our collaboration was not without friction. Having developers from two different teams means overhead from two different teams. For example:
- We had periods where the ML Platform team members had to deliver training programs for other parts of the company, and could not devote much time to this project. Similarly, members of the Payments team would occasionally need to attend to unrelated firefighting duties and miss a week of the collaborative project. Clearly communicating these external influences was very important, as the Payments team members are not aware of what is happening in the ML Platform team, and vice-a-versa.
- Sharing knowledge between the two teams was crucial, especially in the early stages of the project. While the Payments' team members are experts at the underlying business domain, the ML Platform team members were not. Similarly, while the ML Platform team members are experienced with the tools used for the project, the Payments’ team members did not have this expertise.
Conclusion and Outlook
Our new system fulfills the requirements of the old system, while addressing its pain points:
- Because we use Amazon SageMaker for the model actions (i.e. training, endpoints, etc.), the system is guaranteed to be independent from the modeling framework.
- Each model served behind a SageMaker endpoint scales more quickly than in the old system, and we can easily increase the number of instances used for model training to speed up our pipeline execution.
- Each stage of the pipeline has a clear purpose and thanks to SageMaker Inference Pipelines, the data processing and model inferencing can take place within a single endpoint.
- Because we are using Zalando ML Platform tooling, our new system takes advantage of technology from AWS, in particular Amazon SageMaker.
We plan to use a similar architecture in other data science products.
The project was a successful test of a team collaboration across departments, and proved that such collaboration can bring great results.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Applied Scientist!

