Tracing SRE’s journey in Zalando - Part III
Follow Zalando's journey to adopt SRE in its tech organization.

Principal Software Engineer
This is the third and last part of our journey to roll out SRE in Zalando. You’ll find the previous chapters here and here. Thanks for following our story.
2020 - From team to department
The road so far: 2016 saw an attempt at the rollout of a Site Reliability Engineering (SRE) organization that did not quite materialize but still left the seed of SRE in the company; in 2018 and 2019 we had a single SRE team working on strategic projects that improved the reliability of Zalando’s platform. The success of that last team brought with it many requests for collaboration, which had to be balanced with SRE’s own roadmap. In this chapter we’ll learn how SRE adapted in order to achieve sustainable growth.
In late 2019 there was a reorg in our Central Functions unit. This reorg was centered around a set of principles, chief among them were ”Customer Focus”, “Purpose” and “Vision”. Through that reorg SRE becomes a department that encompasses the original SRE Enablement team, the teams building monitoring services and infrastructure, and incident management. This is a clear investment from the company into the value SRE repeatedly demonstrated. The close collaboration those teams had had in the previous years already hinted at a common purpose between them. Through the Incident Commander role and the support to Postmortems, SRE was always in close contact with Incident Management. Distributed Tracing, where SRE invested much of its efforts, was actually owned by one of the monitoring teams. Now that everyone was under the same ‘roof’ we could further strengthen the synergies that were already in place.
![]()
In 2019 SRE had already started to dedicate time to its own products, but the creation of a department further endorsed SRE’s long term plans. But with an entire department under the SRE label, we had to be smart about our next steps. Particularly in the long term. Also, we had to adjust to what it meant operating as a department. Before, with a single team we could be (and occasionally had to be) more flexible, picking ad hoc projects. But now we had teams with a better defined purpose. And we wanted to have all teams working together towards a common goal. It was time to come up with a plan for how we could implement our new purpose: to reduce the impact of incidents while supporting all builders at Zalando to deliver innovation to their users reliably and confidently. That plan was materialized into the SRE Strategy, which was published in 2020, and it set the path for the years to come.
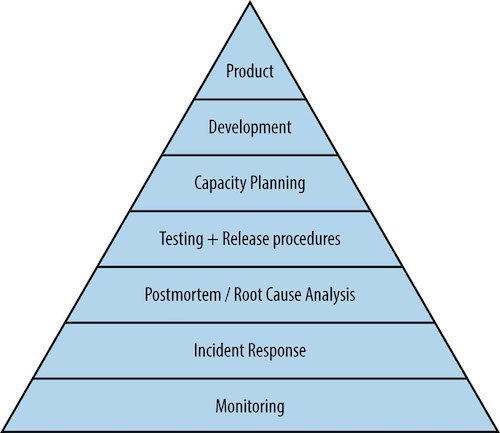
Following the same set of principles that influenced the creation of the SRE department (”Customer Focus”, “Purpose” and “Vision”), the SRE Strategy had at its core Observability. How did Observability fit with those principles and bound the three teams? For the teams developing our monitoring products it’s quite obvious. But Observability is also key for SRE: we drive our work through SLOs, and it is at the base of the Service Reliability Hierarchy. Finally, Incident Management is made that much more efficient with the right Observability into our systems, by identifying issues in our platform, and also making it easier to understand what is affecting the customer experience.
Our strategy set a target standardizing Observability across Zalando. Through that standardization we could achieve a common understanding of Observability within the company, reduce overhead of operating multiple services and make it easier to build on top of well defined signals (like we did before with OpenTracing). The concrete step for making this possible was to develop SDKs for the major programming languages at use in Zalando. Standardization was something we grew quite fond of in the previous years. While operating as a single team, doing several projects with different teams we were uniquely positioned to identify common pain points or inefficiencies across the company. But eventually we also realised one thing: as a single team it would be challenging to scale our enablement efforts to cover hundreds of teams in the company. Waiting for the practices we tried to establish to spread organically would also take too long. The only way we could properly scale our efforts and reach our goals, was to develop the tools and practices that every other team would use in their day to day work. We couldn’t do everything at once, but our new strategy gave us the starting point: Observability.
We started collecting metrics on our performance regarding Incident Response. How many incidents were we getting? What was the Mean Time To Repair? How many were false positives? What was the impact of those incidents? Now that incident management was part of SRE, it was important to understand how the incident process was working, and how it could be improved. We were already rolling out Symptom Based Alerting, so that alone would already help with reducing the False Positive Rate. But we took it a step further and devised a new incident process that separated Anomalies and Incidents. It’s easy to map these improvements to benefits for the business and to our customers, but there’s also something to be said about the health of our on-call engineers. Having an efficient incident process (and the right Observability into a team’s systems), goes a long way to making the lives of on-call engineers better. Pager fatigue is something that should not be dismissed, and can hurt a team through lower productivity and employee attrition. Something important to highlight in this whole process is that we started by collecting the numbers to see if they would match what our observations had already been pointing to. This is a common practice that guides our initiatives. That is also why one of the first things we did after creating the department was to define the KPIs that would guide our work, make sure they were being measured, and facilitate the reporting of those KPIs.
SRE continued the rollout of Operation Based SLOs by working closely with the senior management of several departments and agreeing on their respective SLOs. Those SLOs would be guarded by our Adaptive Paging alert handler. With this we also continued the adoption of Symptom Based Alerting. With Adaptive Paging we had an interesting development. Our initial approach was to make the SLO the threshold upon which we would page the on-call responder. What we soon discovered is that it made our alerts too sensitive to occasional short lived spikes, similar to any other non-Adaptive Paging alert. We mitigated this by providing additional criteria that engineers could use to more granularly control the alert itself (time of day, throughput, length of the error rate). What initially was supposed to be a hands off task for engineers (defining alerts and thresholds), quickly led us down a path we were already familiar with. Engineers were back at defining alerting rules because the target set by the SLO was not enough. After some experiments, we improved Adaptive Paging by having it use Multi Window Multi Burn Rate alert threshold calculation. This change resulted in two relevant outcomes. First, it brought Error Budgets to the forefront. Deciding whether to page someone or not was no longer whether the SLO was breached or not, but rather whether the Error Budget was in risk of being depleted or not. The second outcome, and arguably more important, is that we made it possible for the operations guarded by our alert handler to have their respective rules (length of the sliding windows and the alarm threshold) derived automatically from the SLO without any effort from the engineering teams, which was usually done through trial and error.
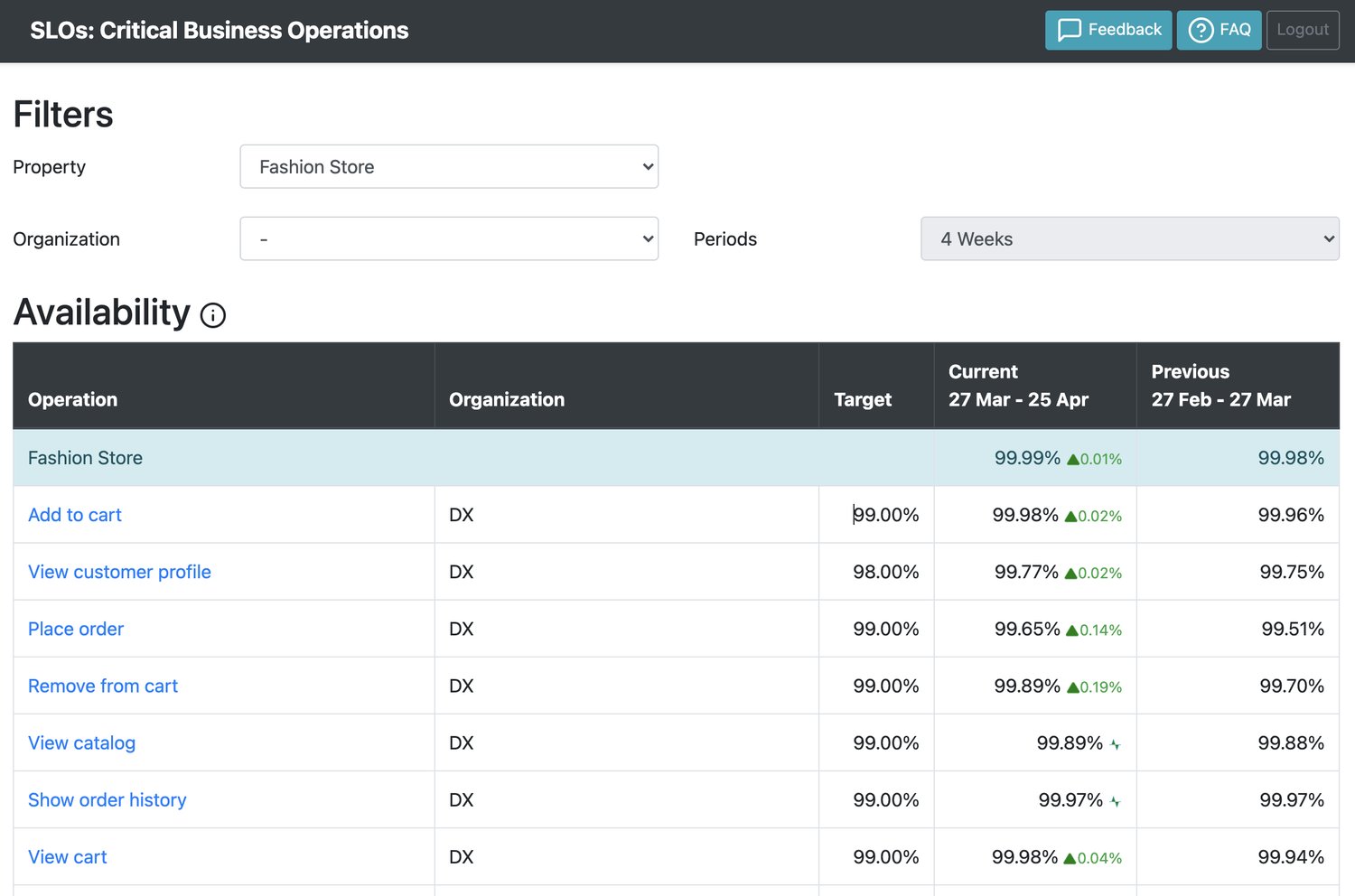
The challenge with rolling out Operation Based SLOs was that reporting and getting an overview of those SLOs was not easy, with the data fragmented in different tools. To address this issue, a new Service Level Management tool was developed. As we evolved the concept of SLOs, so too did we evolve the tooling that supported it. Other than reporting SLOs for the different operations, we also gave a view on the Error Budget. Knowing how much Error Budget is left makes it easier to use it to steer prioritization of development work.
Late in 2020 we began developing what we called the SRE Curriculum. This was an initiative that aimed at scaling the educational benefits of SRE. Specifically, this meant sharing the wealth of knowledge that SREs have accumulated over time about the sharp edges of production. We were looking not only at raising the bar on the company’s operational capabilities, but also to facilitate any interactions with other teams by providing a common understanding on the topics covered by the curriculum. In the previous years we did several training sessions for incident response, distributed tracing, and alerting strategies. These were ad hoc engagements when teams requested our support. With the advent of the pandemic, many things changed and we had to adapt. Those training sessions were one of those things. The format for those sessions was based on having them in person. We did try to do some via video conference, but it did not have quite the same result. At the same time, the company’s Tech Academy was facing the same challenges. We grouped together to develop a new series of training sessions in a new format. The deliverables of this new format were a video and a quiz for each topic, with the content of each training being created and reviewed by subject matter experts to ensure a common understanding and a high quality training. This way we captured the knowledge that could be consumed by anyone in the company at any given time and different pace. Also, by having those training sessions part of the onboarding process, any engineer joining Zalando would get an introduction to some of the SRE practices we were rolling out.

The support of the SRE Enablement team is still in high-demand for ad hoc projects. After another collaboration between SRE and the Checkout teams, the senior management of that department officially pitched for the creation of an Embedded SRE team. This is something we had in the back of our minds for further down the road. But to have it being requested by another department was an interesting development. In any case, here we were. This development presented quite a few new challenges (and opportunities):
- What will the team work on? What will its responsibilities be?
- Who will the team report to?
- Is this time bound? Or is it a permanent setup?
- If they report to separate departments, how will they review the collaboration? Or how do we do performance evaluation effectively for SREs working in a different department?
- How will the embedded SRE team collaborate with the product development team?
- How will the embedded team keep in sync with the central team?
The Embedded team will report to the SRE department, and both SRE and product area management have aligned on a set of KPIs like Availability and On Call Health. The former will be dictated by the SLOs defined for that product area, but the latter aims at making sure the operational aspect is not having its toll on the product development team. On-call Health will be measured taking into account paging alerts and how often an individual is on-call.
We’re still figuring out most things as we go along, but this is an exciting development. This team will be different from the Enablement team, in the sense that it will have a much more concrete scope. This team will be able to be more hands-on on the code and tooling used within the product development team. It will be a voice for reliability within that product area, able to influence the prioritization of topics which ensure a reliable customer experience in our Fashion Store. The SRE department will also benefit from having a source providing precious feedback on whatever the department is trying to roll out to the wider engineering community.
You may remember from our last article where we mentioned that hiring was always a challenge (a topic you can also read from the experience of other companies that rolled out SRE). Now we’re planning to bootstrap another team, so that cannot be making things any easier. But the truth is that having a department with teams which were different in nature also had an unexpected benefit in our hiring. Before, our capacity constraints prevented us from hiring anyone who wasn't a good fit for the original position with the plan to further develop those people and establish the SRE mindset. Now we have the possibility to have a candidate with potential to join one of the teams in the department, and from there grow into the SRE role. Whether later they join the SRE Enablement team or not is not that important (although team rotation is something that is quite active in Zalando). Any team can benefit from having someone with the SRE mindset. Also, we strive for close collaboration within the department, so it’s not like engineers are isolated in their respective teams.
And this is it, mostly. You are all caught up with how SRE has been adopted in Zalando, and what we’ve been up to. And what a ride it has been! Attempting to create a full SRE organization, later starting with a single central team, reaching the limits of that team, creating a department, further growing that department with an embedded SRE team… Were we 100% successful? No (also, SREs don’t believe in 100%). But we’ve done the Postmortem where we failed, and the learnings we got from there turned into action items in our strategy. This has been working really well for us, but there’s still so much to do. There are many interesting ways that SRE can develop into, so we’re really excited to see what challenges we’ll get next. Until we reach our next stage of evolution, we’ll keep doing what we do best: dealing with ambiguity and uncertainty. And help Zalando ensure customers can buy fashion reliably!
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Backend Engineer!