Zalando's Machine Learning Platform
Architecture and tooling behind machine learning at Zalando

Senior Software Engineer
To optimize the fashion experience for 46 million of our customers, Zalando embraces the opportunities provided by machine learning (ML). For example, we use recommender systems so you can easily find your favorite shoes or that great new shirt. We want these items to fit you perfectly, so a different set of algorithms is at work to give you the best size recommendations. Our demand forecasts will ensure that everything is in stock, even when you decide to make a purchase in the middle of a Black Friday shopping spree.
As we grow our business, we look for innovative ideas to improve user experience, become more sustainable, and optimize existing processes. What does it take to develop such an idea into a mature piece of software operating at Zalando's scale? Let's look at it from the point of view of a machine learning practitioner, such as an applied scientist or a software engineer.
Experimenting with Ideas
Jupyter notebooks are a frequently used tool for creative exploration of data. Zalando provides its ML practitioners with access to a hosted version of JupyterHub, an experimentation platform where they can use Jupyter notebooks, R Studio, and other tools they may need to query available data, visualize results, and validate hypotheses. Internally we call this environment Datalab. It is available via a web browser, comes with web-based shell access and common data science libraries.
Because Datalab provides pre-configured access to various data sources within Zalando, such as S3, BigQuery, MicroStrategy, and others, its users don't have to worry about setting up the necessary tools and clients on their own laptops. Instead, they're ready to start experimenting in less than a minute.
While Datalab is well suited for prototyping and getting quick feedback, it's not always enough, especially when big data is involved. Apache Spark is much better suited for that purpose, and Zalando users can access it via Databricks. It's a well-known tool within the data science community, suitable for both experimentation via notebooks and for running large-scale data processing jobs in Spark clusters.
Some experiments require extra processing power, e.g. when they involve computer vision or training of large models. For these purposes, our applied scientists have access to a high-performance computing cluster (HPC) equipped with powerful GPU nodes. Using the HPC is as easy as connecting to it via SSH.
ML Pipelines in Production
One of the most frequently discussed problems in machine learning is crossing the gap between experimentation and production, or in more crude terms: between a notebook and a machine learning pipeline.
Jupyter notebooks don't scale well to requirements typical for running ML in a large-scale production environment. These requirements include secure and privacy-respecting access to large datasets, reproducibility, high performance, scalability, documentation, and observability (logging, monitoring, debugging). A machine learning pipeline is a sequence of steps that can meet these additional requirements, and describes how the data will be extracted and processed, what is the required hardware infrastructure, and how to train and deploy the model. Additionally, ML pipelines at Zalando should follow best practices of software engineering: the code needs be stored in git, clean, readable, and reviewed by at least two people. An ML pipeline can be visualized as a graph, like the one shown below.
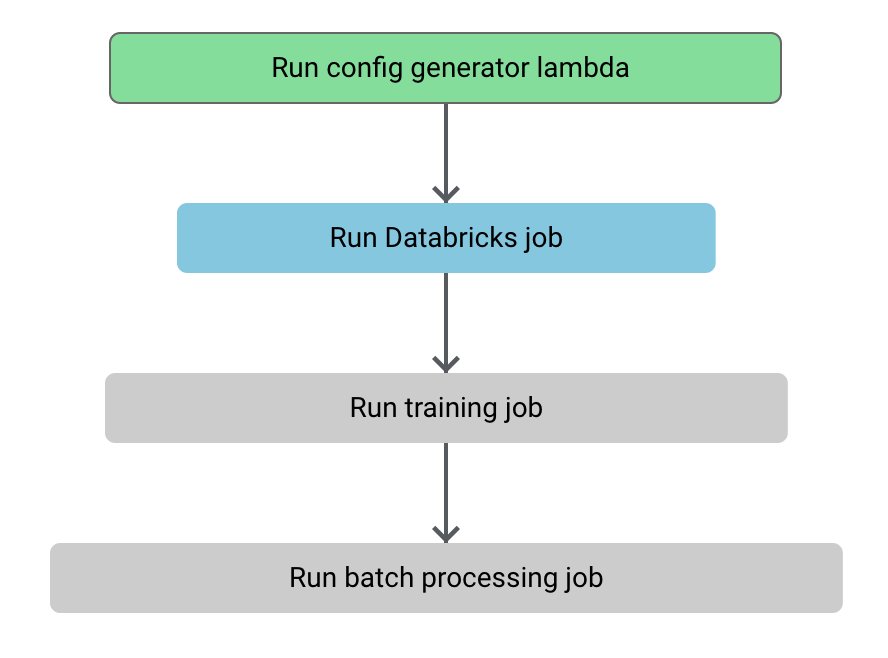
But how does one implement such a pipeline? In early 2019 we at Zalando decided to use AWS Step Functions for orchestrating machine learning pipelines. Step Functions is a platform for building and executing workflows consisting of multiple steps that may call various other services, such as AWS Lambda, S3 and Amazon SageMaker. These calls can be used to perform all steps comprising an ML pipeline, from data processing (e.g. by invoking Databricks API), to running training and batch processing jobs in Amazon SageMaker and creating SageMaker endpoints for real-time inference. The fact that Zalando already used AWS as its main cloud provider, and the flexibility provided by integrations with other services made Step Functions a good fit for our machine learning needs.
A Step Functions workflow is a state machine that can either be created visually using an editor provided by AWS or deployed as a JSON or YAML file known as a CloudFormation (CF) template. CloudFormation is another AWS service that implements the concept of infrastructure as code, and allows developers to specify needed AWS resources in a text file. We can thus use a CF template to describe Lambda functions and security policies used by the Step Functions workflow that is our ML pipeline. After the template is deployed to AWS, CloudFormation will create all resources listed in the file.
CloudFormation templates are highly expressive and allow developers to describe even minute details. Unfortunately, CF files can become verbose and are tedious to edit manually. We addressed this problem by creating zflow, a Python tool for building machine learning pipelines. Since its creation, zflow has been used to create hundreds of pipelines at Zalando.
A pipeline in a zflow script is a Python object with a series of stages attached to it. zflow provides a number of custom functions for configuring ML tasks, for example training, batch transform, and hyperparameter tuning. It also offers flow control so stages can be run conditionally or in parallel. Together these functions form a Domain Specific Language (DSL) for describing pipelines in a concise and readable form. Because zflow code is annotated with type hints, users can spot mistakes early on, and the available warnings go beyond simple syntax checks available for JSON and YAML templates.
The code listing below demonstrates an example zflow pipeline, with some configuration options omitted for brevity. It shows how three stages are created and added to a pipeline in the desired order. The pipeline is then added to a stack (a group of CloudFormation resources). The last line specifies where the resulting template should be saved.
data_processing = databricks_job("data_processing_job")
training = training_job("training_job")
batch_inference = batch_transform_job("batch_transform_job")
pipeline = PipelineBuilder("example-pipeline")
pipeline \
.add_stage(data_processing) \
.add_stage(training) \
.add_stage(batch_inference)
stack = StackBuilder("example-stack")
stack.add_pipeline(pipeline)
stack.generate(output_location="zflow_pipeline.yaml")
When a pipeline script is executed, zflow uses AWS CDK to generate a CloudFormation template file. The file contains all the information needed to create the necessary AWS resources. All that is needed now is to commit and push the generated template to the git repository and let Zalando Continuous Delivery Platform (CDP) deploy it to AWS. When that is done, our pipeline will appear in the AWS Console as a Step Functions state machine. It can then be executed, either via scheduler (like in our example), manually in the Console, or programatically via an API call.
With zflow, a pipeline can be coded in a concise way, tested, then versioned in a git repository, deployed, run, and scaled as needed. To ensure that it works as expected, we can track its executions using a custom web interface. Pipeline tracking is a part of the internal Zalando developer portal running on top of Backstage, an open-source platform for building such portals. Here a screenshot of a series of pipeline executions in the ML portaI.
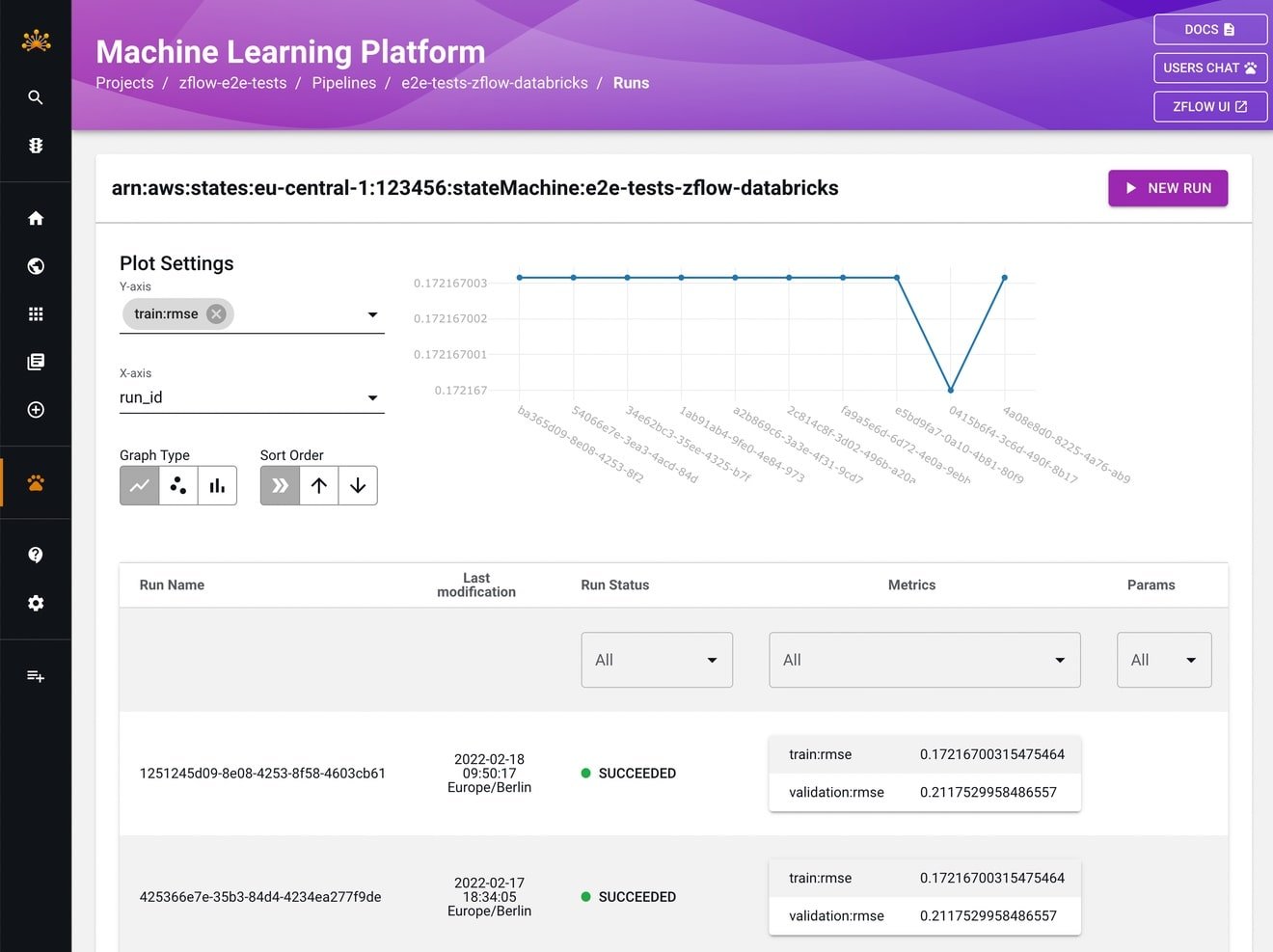
This ML web interface provides a detailed, real-time view of pipeline execution. Pipeline authors can monitor how metrics evolve across multiple runs of training pipelines and can view these changes on a graph. They can also view model cards for models created by the pipelines. These are just a few features of the ML portal, and the tool is actively developed to improve the process of experimenting with notebooks and deploying the pipelines in production.
The detailed journey of a pipeline is shown in the diagram below.

Admittedly, that's a lot to take in! Let's summarize the steps and tools we discussed so far:
- We use JupyterHub, Databricks, and a high-performance computing cluster for ML experimentation.
- We describe our ML pipelines in Python scripts with zflow DSL. Pipelines can use various resources, such as Databricks jobs for big data processing and Amazon SageMaker endpoints for real-time inference.
- When we run the pipeline script, zflow will internally call AWS CDK to generate a CloudFormation template.
- We commit and push the template to a git repository, and Zalando Continuous Delivery Platform will then upload it to AWS CloudFormation.
- CloudFormation will create all the resources specified in the template, most notably: a Step Functions workflow. Our pipeline is now ready to run.
- A web portal built with Backstage provides a visual overview of running pipelines, together with additional information relevant to ML practitioners.
zflow and the dedicated web UI abstract away most of the complexity of building production pipelines with AWS tooling, such as CDK and CloudFormation, so ML practitioners can focus on their domain rather than the infrastructure. While zflow takes full advantage of AWS, it also allows us to integrate other tools used within the company and to quickly respond to our specific needs.
The Organization
Tooling is just one side of using any technology. Another aspect is the organizational structure that allows experts to work and collaborate effectively. While applying ML within the company, Zalando uses a distributed setup with additional resources in place to support reusing tools and practices across the organization. Most expertise is spread across over a hundred product teams working in their specific business domains. These teams have dedicated software engineers and applied scientists who in their daily work use both 3rd party products (e.g. AWS, Databricks) and internal tools (zflow, ML web portal).
Our experts are assisted by a few central teams which operate and develop some of the aforementioned tools. For example, a dedicated team provides support and improvements to our JupyterHub installation and the HPC cluster. Two teams actively develop zflow and monitoring tools for pipelines. Another group consisting of ML consultants works closely with product teams, offering trainings, architectural advice, and pair programming. A separate research team actively explores and disseminates the state-of-the-art in algorithmics, deep learning, and other branches of AI.
On top of that, our data science community provides platforms to exchange best practices from internal teams, academia, and the rest of the industry through expert talks, workshops, reading groups, and an annual internal conference.
Exciting Times
Teams at Zalando tackle many of the difficult problems in the space of machine learning and MLOps, such as reducing the time needed to validate and implement new ideas at scale and improving model observability. We constantly look for new ways to use technology to be faster, more efficient, and innovative in meeting all fashion-related needs of our customers. Best news: we would like to work with you on these exciting ML challenges!
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Data Engineer!






