How we manage our 1200 incident playbooks
We consolidated our incident playbooks in September 2019. 1200 playbooks later...

Executive Principal Engineer
At Zalando, we use Incident Playbooks to support our on-call teams with emergency procedures that can be used to mitigate incidents. In this post, we describe how we structured incident playbooks, and how we manage these across 100+ on-call teams.
Incident Playbooks - where are we now?
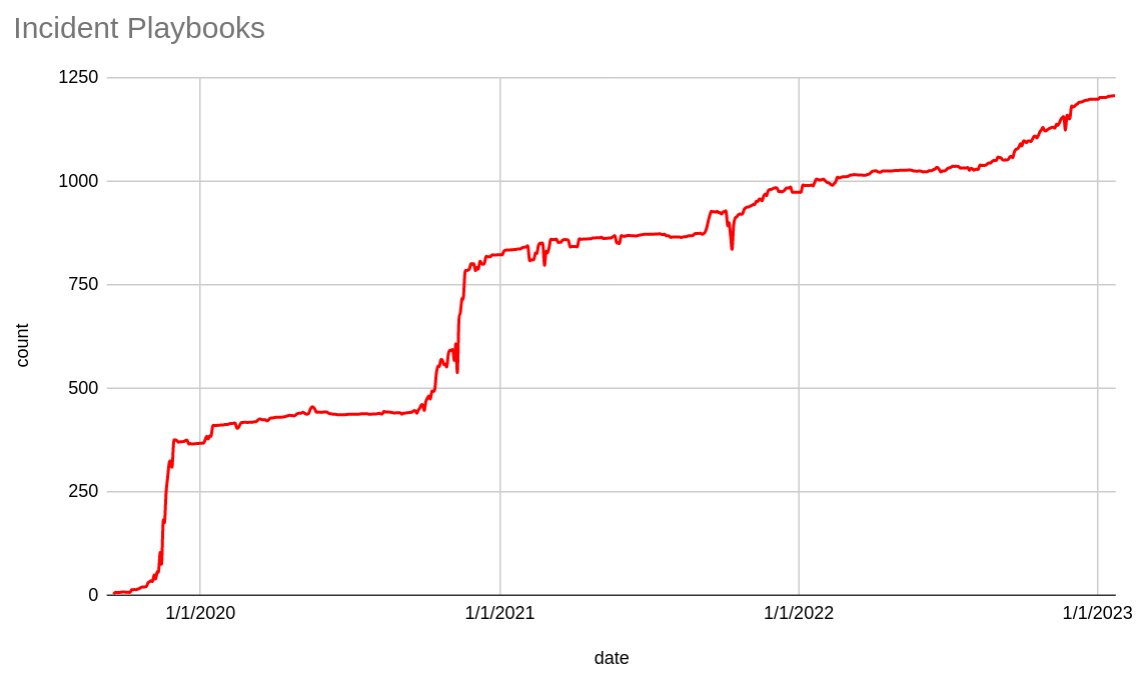
We consolidated our incident playbooks as part of preparation for Cyber Week in 2019. Fast forward to 2023 and we have over 1200 playbooks that our teams have authored. Given the 850+ applications in scope for on-call coverage across 100+ on-call teams, that's 1.41 playbooks per application and ca. 12 playbooks per on-call team. The diagram below shows how our playbook collection has increased over the years. It's easy to see how Cyber Week preparations in Q3 of each year result in significant increases in the playbook collection.
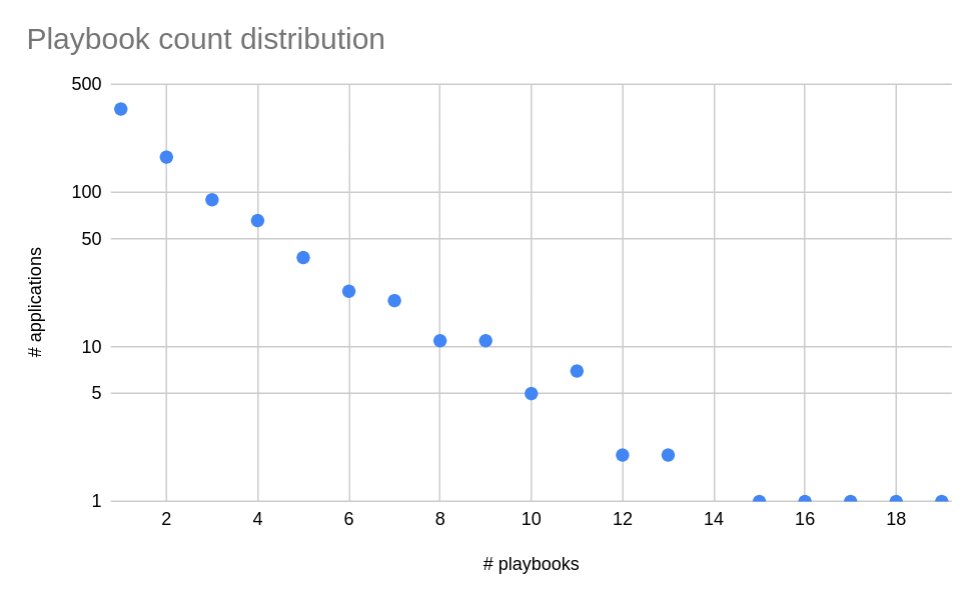
As expected, most applications have just a few playbooks. Below, you can see the number of applications per playbook count.
What are incident playbooks?
Our Incident Playbooks cover emergency procedures to initiate in case a certain set of conditions is met, for example when one of our systems is overloaded and the existing resiliency measures (e.g. circuit breakers) are insufficient to mitigate the observed customer impact. In such cases there are often measures we can take, though they will degrade the customer experience. These emergency procedures are pre-approved by the respective Business Owner of the underlying functionality, allowing for quicker incident response without the need for explicit decision making while critical issues are ongoing.
Further, playbooks make incident response less stressful for colleagues on on-call rotations. Each on-call member takes the time to become familiar with the procedures and understands the toolbox they have available during incidents. New playbooks are reviewed by the on-call team, shared as part of on-call handover or operational reviews, and practiced in game days, or as part of preparation for big events.
The procedures document the conditions (e.g. increased error rates), business impact (e.g. conversion rate decrease), operational impact (e.g. reduction of DB load), mean time to recover, and the steps to execute. This structure allows all stakeholders involved in incident response to clearly understand the executed actions and target state of the system to expect. Lastly, by having playbooks in a single location, our Incident Responders and Incident Commanders have easy access to all available emergency procedures in a consistent format. This simplifies collaboration across teams during outages.
More often than not, our playbooks cover the whole system (a few microservices) instead of its individual components being covered through separate procedures. When the bigger system context is considered, there are more options available to mitigate issues.
When we started in 2019, we first focused on a collection of procedures that were already known, but not consistently documented. Next, as part of the Cyber Week preparations we wanted to explore and strengthen the mechanisms we have in place to mitigate overload or capacity issues across the different touchpoints of the customer (e.g. product listing pages) and partner journeys (e.g. processing of price updates).
Let's consider two examples:
1) Product Listing Pages (aka. catalog)
Our catalog pages integrate multiple data sources, such as teasers, sponsored products, and outfits. Fetching data from all sources comes at increased costs compared to a simple article grid. Therefore, we have a set of playbooks that disable the different data sources in order to reduce the load on the backends providing the APIs and the underlying Elasticsearch cluster. The playbooks are sorted in such way that we apply the playbooks with least business impact first. In one of our evening Cyber Week shifts, we encountered performance degradation resulting in increased latencies, which was hard to diagnose. While one part of the team was busy troubleshooting the issue, another part of the team executed multiple of the prepared playbooks in sequence in order to mitigate the customer impact.
Example playbook for catalog:
- Title: Disable calls for outfits in the Catalog’s article grid
- Trigger: High latency for fetching outfits for the article grid or High CPU usage for Elasticsearch's outfit queries
- Mean time to recover: 3 minutes after updating configuration
- Operational Health Impact: No more outfit calls from Catalog, reduced request rates to Elasticsearch by x%.
- Business Impact: Outfits won't be shown as part of the catalog pages.
2) Monitoring system
Our monitoring system ZMON had a component ingesting metrics data and storing these in KairosDB TSDB, backed by Cassandra. Pre-scaling of the Zalando platform for Cyber Week peak workload resulted in a multi-factor increase in metrics pushed by the individual application instances, resulting in ingestion delays due to Cassandra cluster overload. To mitigate similar incidents, we developed a tiering system with three criticality tiers for the metrics, so that in case of overload of the TSDB, we could still ingest the most important metrics necessary to plot essential dashboards required to monitor the Cyber Week event. This playbook is still in place today, even though we changed our metrics storage.
Example playbook for ZMON:
- Title: Drop non-critical metrics due to TSDB overload
- Trigger: Metrics Ingestion SLO is at risk of being breached (link to alert/dashboard)
- Mean time to recover: 2 minutes after updating configuration
- Operational Health Impact: Loss of tier-3 and tier-2 metrics. Only tier-1 metrics are processed, leading to 40% load reduction on the metrics TSDB.
- Business Impact: None
How do we author playbooks?
We use documentation site built using mkdocs to host the documentation containing a description of the incident process and all playbooks. We generate the playbook directory structure based on our OpsGenie on-call teams. This way there is always a skeleton available for every team to contribute their playbooks to. When we started in 2019 we had a team of 3 reviewers, who as part of the playbook reviews were committed throughout the year to explain the purpose/guidance of the playbooks and align these to a common standard. With sufficient examples and knowledge spread across the organization, we switched to using CODEOWNERS to delegate the reviews to representatives of the departments, skilled in operational excellence.
To remind new contributors about our playbook guidelines, we use a pull request template with a few check boxes as means for self-verification of playbook completeness. The 1st line of the template contains a TODO with a nudge for a 1-line summary of the changes. This proved to an easy way of providing reviewers with more context about the performed changes.
Integrating playbook data with application reviews
Aside from the information about triggers and impact for playbooks, we also collect additional metadata allowing us to integrate playbooks with our application review process:
- Application – links playbooks to the involved applications
- Expiry date – allows to nudge teams to re-review playbooks that will expire soon
To keep integration simple, along with the documentation, we also generate a JSON file with playbook metadata. During the application review process it's indicated per application (from certain criticality tier onward) whether there are any playbooks defined for it and whether any of these are expired.
With time, we made it mandatory for applications of certain criticality to have an assigned playbook. This partially increased the scope of the playbooks beyond the key emergency procedures while at the same time providing training to our engineers in the authoring of playbooks and thinking about the overload and failure scenarios that can occur.
Summary
When we initially created the incident playbooks site, maintenance of playbooks as markdown files was considered to be good means for ensuring consistency, but rather of temporary nature. To be consistent with our UI-driven application review workflow, we intended to manage playbooks in the same way. Managing structured data in markdown is not ideal, despite the ability to use front matter for metadata. However, managing playbooks in a code repository provides us with easy means for cross-team reviews using pull requests. This key advantage keeps us from moving to a UI-driven workflow where such collaboration would be limited.
We can certainly recommend every team to think about the failure scenarios their systems can experience, for example as part of production readiness reviews or game days. Without them, there are several key incidents that would have had a markedly larger impact on our customer experience.
Imagining how to react to such scenarios by putting the system into a degraded state, trading off availability over customer experience, can spark interesting conversations about resilience mechanisms that can be built into the software. These conversations drive engineers to make changes to their design to fundamentally improve availability, or at least, to ensure their software facilitates easier intervention.
If used often enough, playbooks should be ideally automated.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Backend Engineer!

