How Software Bill of Materials change the dependency game
In this post, we explain what questions and insights Software Bill of Materials (SBOMs) provide across thousands of microservices

Executive Principal Engineer
Dependency hygiene
Dependency updates are a tedious task when maintaining thousands of microservices. Some teams use tools like dependabot, scala-steward that create pull requests in repositories when new library versions are available. Other teams update dependencies regularly in bulk, supported by build system plugins (e.g. maven-versions-plugin, gradle-versions-plugin). Playing the catch-up game and getting some visibility through incoming pull requests or changes is far from great, though and we can do better here.
On the importance of dependency data and hygiene
What's needed for dependency management is the ability to get a complete picture of used dependencies over time and analyze trends over time. This granular data allows teams to step up their game.
Critical vulnerabilities in commonly used libraries (e.g. log4j, spring, commons-text) require an ability to find all affected applications in minutes. Only this way can the impact of a vulnerability be assessed and mitigated quickly. Some projects, like openssl, preannounce security updates allowing for more preparation time.
Similarly, upgrades to major versions of libraries, changes in licensing of open-source libraries (for example Akka) create the need to understand the library footprint to assess the need for action or migration costs. Bugs in libraries tend to eventually trigger production incidents and it's necessary to have a way to find all affected teams, track progress of patches across all applications, and identify reasons why teams struggle to keep up.
At Zalando, we use Software Bill of Materials (aka. SBOMs) to help answer various questions about application dependencies. We publish a curated data set containing dependency data from the SBOM for every application we deploy, based on its Container image. The data set is available in our data lake and thus can be easily queried and visualized by any engineer.
What are SBOMs?
The Software Bill of Materials contains information about the packages and libraries used by an application. It can be generated for an application based on its source code or extracted from a Docker container. The SBOM includes packages used by the operating system as well as the application and its dependencies. For each entry, the name, version, and license is tracked. Common formats like CycloneDX or SPDX help with portability and integration into various tooling. For example, syft can generate an SBOM file that can be further parsed with grype to periodically scan the application's SBOMs for vulnerabilities. On top, GitHub introduced recently an on-demand SBOM generation feature.
The SBOM needs to be generated with every software change, for example as part of the CI/CD pipeline. Some countries recommend or even mandate the use of SBOMs in certain scenarios in order to manage cyber security and software supply chain risks (see Securing the Software Supply Chain: Recommended Practices Guide for Developers).
What questions can the SBOM help to answer?
In the context of dependency management, SBOMs collected for all applications help us answer a variety of questions:
- Which applications use dependency X (in version Y)?
- How many distinct versions of dependency X do we use across all applications?
- Does the dependency hygiene differ per language?
- How quickly after release, are new versions of libraries adopted? Does adoption differ for versions that have known security vulnerabilities?
- When adopting a new Docker base image, what are its contents?
- Which application has dependencies licensed under license X?
- Which distinct licences are being used by application dependencies?
From Docker image metadata, we can infer the owning team and thus target communication when reaching out to teams. For large-scale patch actions (like the famous log4j upgrade), we prepare change sets for different types of build files and automate the Pull Request creation across all repositories. This allows for central tracking of the patch progress and requires minimal support from the team for the deployment.
Another insight from analyzing the SBOM data was our usage of the AWS SDK. We noticed that some applications were using the full SDK (200MB+ in Java) instead of its individual modules. Addressing this finding helped reduce build times and lower resulting docker image size significantly.
Show me real data!
Our diverse application footprint across languages allows us to perform a comparison of the amount of libraries typical applications have. Looking at the data, the number of dependencies grows exponentially. Here an example for Python:
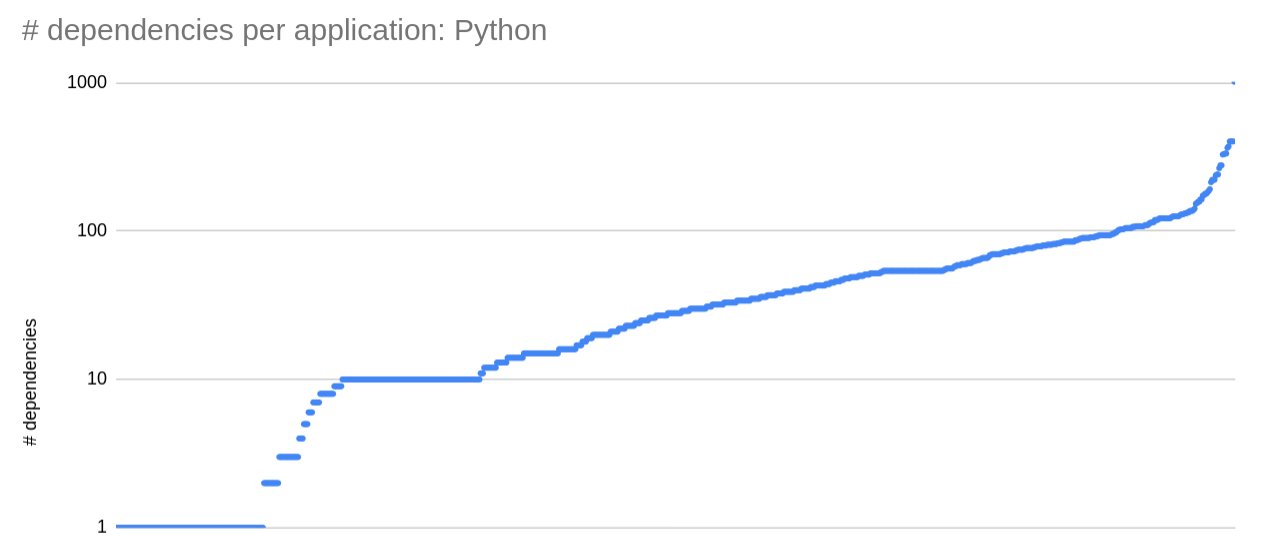
Looking across languages we have two outliers that have the most amount of dependencies. For Python it's jupyter (2.5x next biggest app) and for Java it's tableau (3.14x next biggest app).
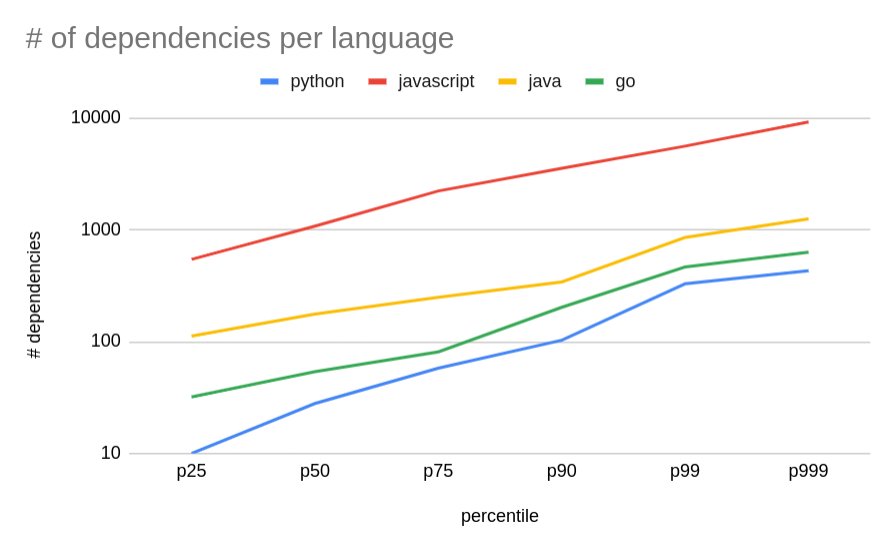
To compare how hungry each language ecosystem is for dependencies, we can plot the percentiles for the number of dependencies per application. Python wins the race with the lowest amount of dependencies, followed by golang (ca. 1.4-2x when compared to Python). Next in line is Java (covers Java, Kotlin, Scala as the SBOM scanner detects java-archives) with 2-3x more dependencies than golang and lastly JavaScript (incl. TypeScript) with 5-10x more dependencies than Java.
Another popular library used across Java and Kotlin projects
This example highlights the challenge with long-term maintenance of a large application footprint. As the frequency of changes to an application reduces, it's more difficult for teams to plan dependency updates for those applications, unless there are security issues to address. The following graph looks at the usage of an internal library with three data snapshots.
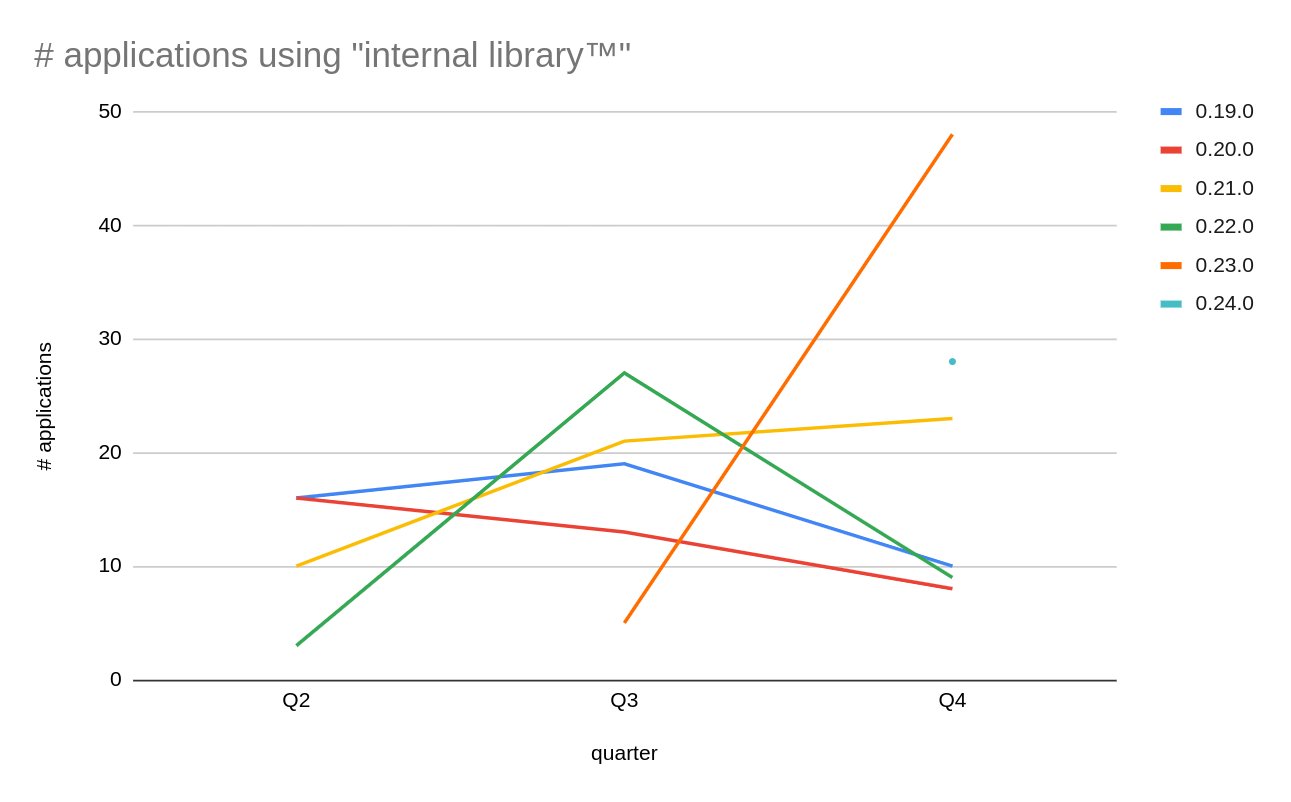
We can see that versions 0.22.0+ exhibit expected behavior by being replaced with the next available version. On the other hand, usage of version 0.21.0 constantly increases, even though three newer versions are available in Q4. This situation requires further inspection. It is likely that new applications are created by using the same application template, which misses the dependency update.
SBOM Data quality
The SBOM data quality varies. For the JVM languages, we observed differing package names, group ids being detected. This increases the complexity of correlating library use across languages. Further, some SBOMs did not show any java-archive entries, because the team's build process flattened all dependencies into an uber-jar and the required metadata needed for library detection was lost. Hence, we recommend caution when using SBOM tools and double-checking that the SBOM generation works correctly for all applications.
Summary and future outlook
In addition to smaller findings like the one with AWS SDK, the value of SBOMs has already been proven with the very low time it takes us to analyze the impact of the Akka license change or CVEs.
We look to dive deeper into our SBOM data as we collect more historical data. Aside from observing trends on library usage and adoption, we hope to be able to correlate dependency data with dependency hygiene practices, deployment frequency, change failure rates, and lead times for each application. For our shared libraries, we aim to understand how to help reduce the burden of dependency updates acknowledging that plugin adoption is insufficient to remain a healthy dependency posture.
If you're not using SBOMs for dependency analysis yet, you're missing out on a great tool helping you to create more transparency. We're curious to read your stories and insights on SBOMs.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Frontend Engineer!