All you need to know about timeouts
How to set a reasonable timeout for your microservices to achieve maximum performance and resilience.

Senior Software Engineer

Engineering Manager
Nobody likes to wait. We at Zalando are not an exception. We don't like our customers to wait too long for delivery, we don't like them to wait during checkout, and we don't like microservices that take too long to respond. In this post we're going to talk about - how to set a reasonable timeout for your microservices to achieve maximum performance and resilience.
Why set timeout
Before we start, let’s answer the simple question: "Why timeout?". A successful response, even if it takes time, is better than a timeout error. Hmm… not always, it depends!
First of all, if your server does not respond or takes too long to respond, nobody will wait for it. Instead of challenging the patience of your users, follow the fail-fast principle. Let your clients retry or handle an error on their side. When possible return a fallback value.
Another important aspect is resource utilisation. While a client is waiting for a response, various resources are being utilised: threads, https connections, database connections, etc. Even if the client has closed the connection, without a proper timeout configuration the request is still being processed on your side, which means that resources are busy.
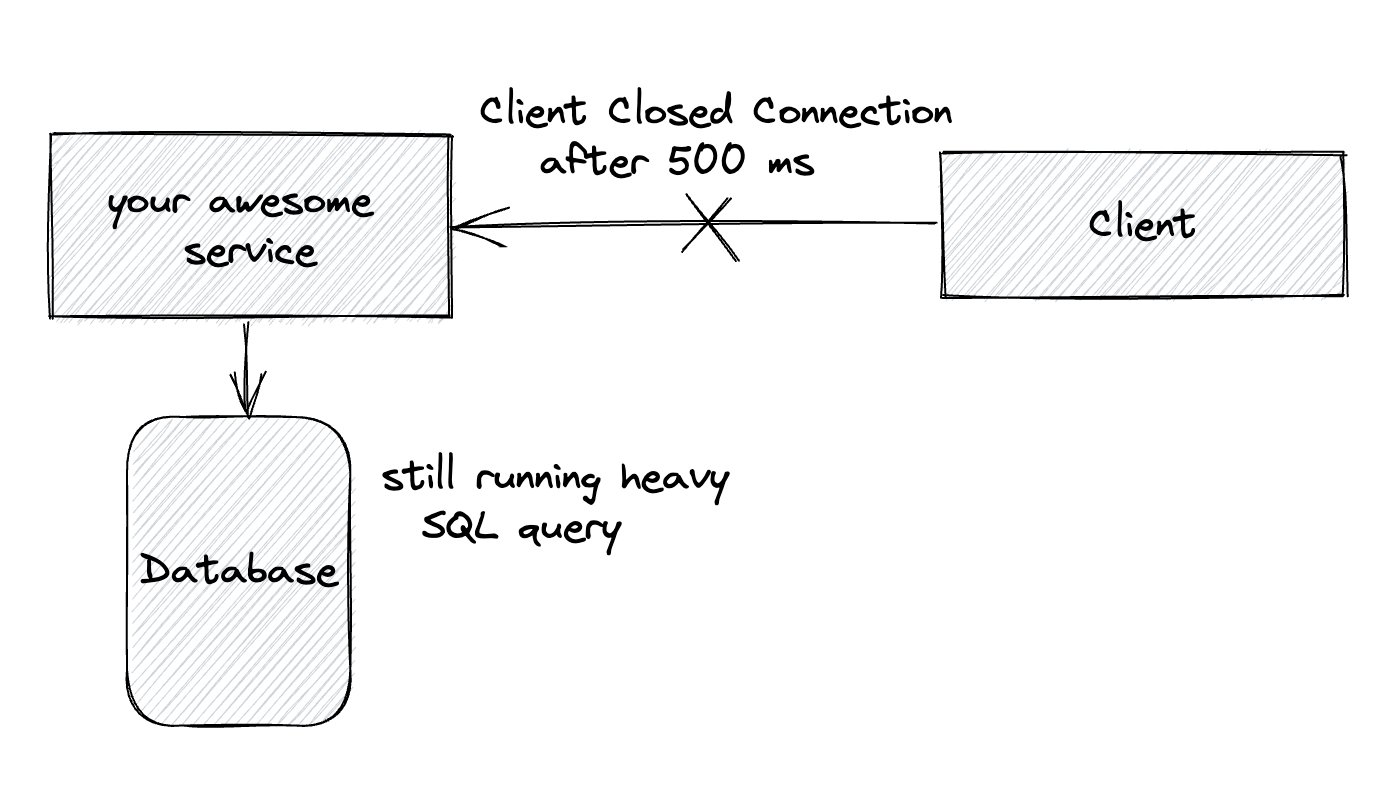
Remember, when you increase timeouts you potentially decrease the throughput of your application!
Using infinite timeout or very high timeout is a bad strategy. For a while, you won't see the problem until one of your downstream services gets stuck and your thread pool gets exhausted. Unfortunately, many libraries set default timeouts too high or infinite. They aim to attract as many users as possible and try to make their library work in most situations. But for production services, it is not acceptable. It can even be dangerous. For example for native java HttpClient the default connection/request timeout is infinite, which is unlikely within your SLA :)
The default timeout is your enemy, always set timeouts explicitly!
Connection timeout vs. request timeout
The distinction between connection timeout and request timeout can cause confusion. First, let's have a look at what Connection timeout is.
If you google or ask ChatGPT you’ll get something like this:
A connection timeout refers to the maximum amount of time a client is willing to wait while attempting to establish a connection with a server. It measures the time it takes for a client to successfully establish a network connection with a server. If the connection is not established within the specified timeout period, the connection attempt is considered unsuccessful, and an error is typically returned to the client.
What does it mean to establish a connection? TCP uses a three-way handshake to establish a reliable connection. The connection is full duplex, and both sides synchronize (SYN) and acknowledge (ACK) each other. The exchange of these four flags is performed in three steps—SYN, SYN-ACK, and ACK.
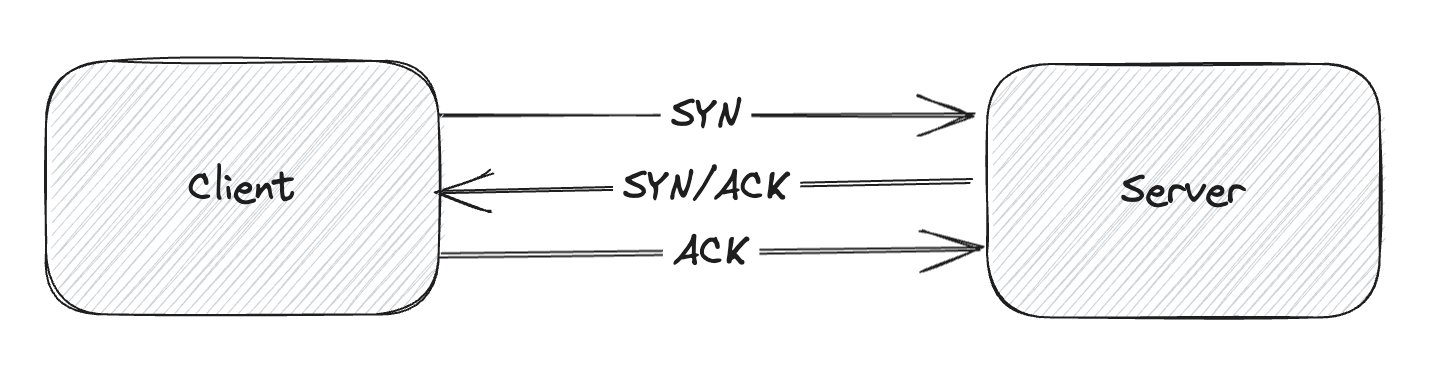
A connection timeout should be sufficient to complete this process and the actual transmission of packets is gated by the quality of the connection.
In simple words, the value for the connection timeout should be derived from the quality of the network between services. If a remote service is running in the same datacenter or the same cloud region, connection time should be low. And the opposite, if you’re working on a mobile application then connection time to a remote service might be quite high.
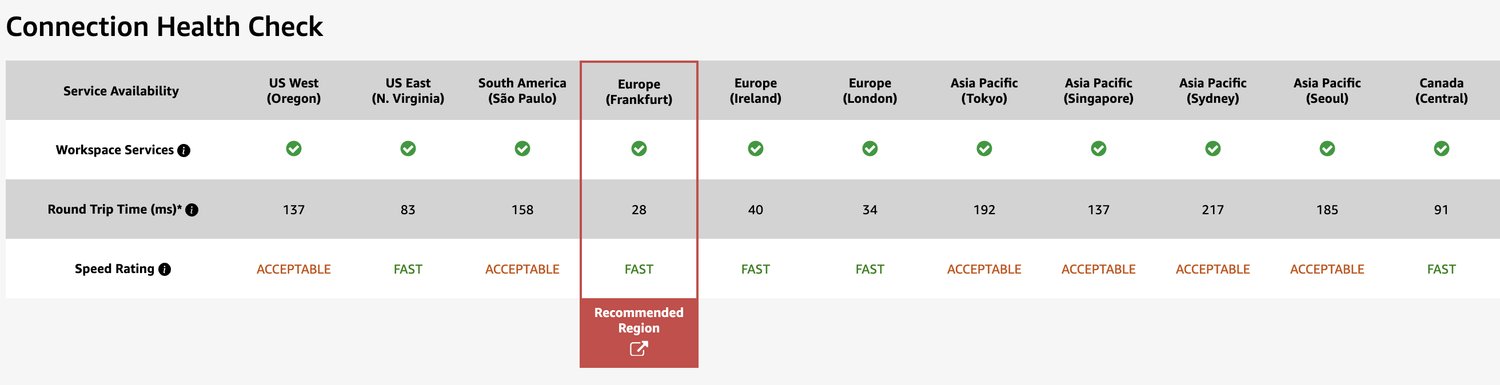
To give you some insights. Round-trip time (RTT) in fiber, New York to San Francisco ~42ms, New York to Sydney ~160ms. You can also look at Connection Health Check by Amazon. This is what I get from my local machine, RTT 28ms to the recommended AWS Region.
When does connection timeout occur
A connection timeout occurs only upon starting the TCP connection. This usually happens if the remote machine does not answer. This means that the server has been shut down, you used the wrong IP/DNS name, the wrong port or the network connection to the server is down. Another frequent condition is when a given endpoint simply drops packets without a response. The remote endpoint's firewall or security settings may be configured to drop certain types of packets or traffic from specific sources.
Connection timeout best practices
A common practice for microservices is to set a connection timeout equal to or slightly lower than the timeout for the operation. This approach may not be ideal since the two processes are different. Whereas establishing a connection is a relatively quick process, an operation can take hundreds or thousands of ms!
You can setup a connection timeout which is some multiple of your expected RTT. Connection timeout = RTT * 3 is commonly used as a conservative approach, but you can adjust it based on your specific needs.
In general, the connection timeout for a microservice should be set low enough so that it can quickly detect an unreachable service, but high enough to allow the service to start up or recover from a short-lived problem.
Request Timeout
A request timeout, on the other hand, pertains to the maximum duration a client is willing to wait for a response from the server after a successful connection has been established. It measures the time it takes for the server to process the client's request and provide a response.
Setting optimal request timeout
Imagine you are going to integrate your microservice with a new API.
The first step would be to look at SLAs provided by the microservice or API you are calling. Unfortunately, not all services provide SLAs and even if they do you should not trust blindly. The SLA value is good enough only for starting to test real latency.
If possible, run an integration with the new API in shadow mode and collect metrics. This code should run parallel to the existing production integration, but without affecting the production system (run it in a separate thread-pool, mirror traffic, etc).
After collecting latency metrics such as p50, p99, p99.9 you can define the so-called acceptable rate of false timeouts. Let's say you go with a false timeout rate 0.1% that means the max timeout you can set is p99.9 corresponding latency percentile on the downstream service.
At this step you have a max timeout value you can set but you have a trade-off:
- set timeout to the max value
- decrease timeout and enable retry
Based on the test results you need to choose the timeout strategy. We'll cover retries a little bit later.
The next challenge you will face is a chain of calls. Imagine your service has SLA 1000ms and it calls sequentially Order Service with p99.9 = 700ms and then Payment Service with p99.9 = 700ms. How to configure timeout and not breach the SLA?

Option 1: Share your time budget One option would be to share your time budget (your SLA) between services and set timeouts accordingly 500ms for Order Service and 500ms for Payment Service. In this case, you have a guarantee that you will not breach your SLA but you might have some false positive timeouts.
Option 2: Introduce a TimeLimiter for your API Since different services will not simultaneously respond with the maximum delay, you can wrap the chained calls in a time limiter and set the maximum acceptable timeout for both services. In this case you could create a time limiter 1sec and set a timeout 700ms for downstream services.
In Java, you could use CompletableFuture and several methods among which are orTimeout and completeOnTimeOut that provide built-in support for dealing with timeouts.
CompletableFuture
.supplyAsync(orderService.placeOrder(...))
.thenApply(paymentService.updateBalance(...))
.orTimeout(1, TimeUnit.SECONDS);
There is also a nice TimeLimiter module provided by the Resilience4j library
Retry or not retry
The idea is simple - consider enabling retry when there is a chance of success.
Temporary failures: Retry is suitable for temporary failures that are expected to be resolved after a short period, such as network glitches, server timeouts, or database connection issues. Retry can also avoid a bad node. Given a large enough deployment (e.g. 100 pods), a single pod might have a substantial performance regression, but if requests are load balanced in a sufficiently random way retrying is faster then awaiting a response from the bad node.
- Retry on timeout errors and 5xx errors
- Do not retry on 4xx errors
Idempotent operations: If the operation being performed is idempotent, meaning that executing it multiple times has the same result as executing it once, retries are generally safe.
Non-idempotent operations can cause unintended side effects if retried multiple times. Examples include operations that modify data, perform financial transactions, or have irreversible consequences. Retrying such operations can lead to data inconsistency or duplicate actions.
Even if you think an operation is idempotent, if possible, ask the service owner whether it is a good idea to enable retries.
For safely retrying requests without accidentally performing the same operation twice, consider supporting additional Idempotency-Key header in your API. When creating or updating an object, use an idempotency key. Then, if a connection error occurs, you can safely repeat the request without the risk of creating a second object or performing the update twice. You can read more about this idempotency pattern here Idempotent Requests by Stripe and Making retries safe with idempotent APIs by Amazon.
Circuit breaker: always consider implementing circuit breakers when enabling retry. When failures are rare, that's not a problem. Retries that increase load can make matters significantly worse.
Exponential backoff: Implementing exponential backoff can be an effective retry strategy. It involves increasing the delay between each retry attempt exponentially, reducing the load on the failing service and preventing overwhelming it with repeated requests. Here is a fantastic blog on how AWS SDKs support exponential backoff and jitter as a part of their retry behaviour.
Time-sensitive operations: Retries may not be appropriate for time-critical operations. The trade-off here is to decrease a timeout and enable retries or keep the max acceptable timeout value. Retries might not work well where p99.9 is close to p50.
Look at the graph, on the first one, timeouts occasionally happens, a big difference between p99 and p50, a good case for enabling retries

On the second graph, timeouts happen periodically, p99 is close to p50, do not enable retries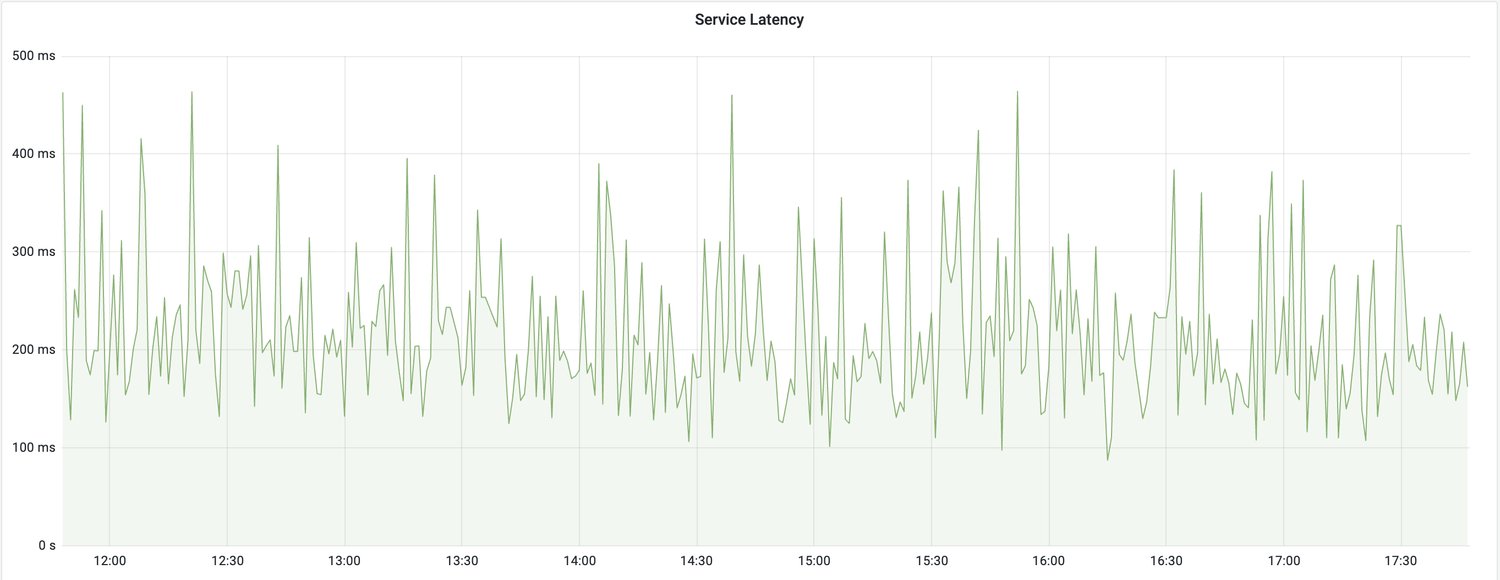
Recap
- set timeout explicitly on any remote calls
- set connection timeout = expected RTT * 3
- set request timeout based on collected metrics and SLA
- fail-fast or return a fallback value
- consider wrapping chained calls into time limiter
- retry on 5xx error and do not retry on 4xx
- think about implementing a circuit breaker when retrying
- be polite and ask the API owner for permission to enable retries
- support Idempotency-Key header in your API
Resources
Speed of Light and Propagation Latency
Timeouts, retries, and backoff with jitter by AWS
The Tail at Scale - Dean and Barroso 2013
The Tail at Scale - Adrian Colyer 2015
The complete guide to Go net/http timeouts by Cloudflare
Handling timeouts in a microservice architecture
Making retries safe with idempotent APIs by AWS
Idempotent Requests by Stripe
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Backend Engineer!


