Patching the PostgreSQL JDBC Driver
Contributing to the PostgreSQL JDBC Driver to address the issue of runaway WAL growth in Logical Replication

Software Engineer
Introduction
This blog post describes a recent contribution from Zalando to the Postgres JDBC driver to address a long-standing issue with the driver’s integration with Postgres’ logical replication that resulted in runaway Write-Ahead Log (WAL) growth. We will describe the issue, how it affected us at Zalando, and detail the fix made upstream in the JDBC driver that fixes the issue for Debezium and all other clients of the Postgres JDBC driver.
Postgres Logical Replication at Zalando
Builders at Zalando have access to a low-code solution that allows them to declare event streams that source from Postgres databases. Each event stream declaration provisions a micro application, powered by Debezium Engine, that uses Postgres Logical Replication to publish table-level change events as they occur. Capable of publishing events to a variety of different technologies, with arbitrary event transformations via AWS Lambda, these event streams form a core part of the Zalando infrastructure offering. At the time of writing, there are hundreds of these Postgres-sourced event streams out in the wild at Zalando.
One common problem that occurs with Logical Replication is excessive growth of Postgres WAL logs. At times, the Write Ahead Log (WAL) growth could occur to the point where the WAL would consume all of the available disk space on the database node resulting in demotion of the node to read-only - an undesirable outcome in a production setting indeed! This issue is prevalent in cases where a table being streamed receives very little to no write traffic - but once a write is made, any excessive WAL growth disappears instantly. In recent years, as the popularity of Postgres-sourced event streams has grown in Zalando, we see this issue occurring more and more often.
So what is happening at a low level during this event-streaming process? How does Postgres reliably ensure that all data change events are emitted and captured by an interested client? The answers to these questions were crucial to understanding the problem and finding its solution.
To explain the issue and how we solved it, we first must explain a little bit about the internals of Postgres replication. In Postgres, the Write Ahead Log (WAL) is a strictly ordered sequence of events that have occurred in the database. These WAL events are the source of truth for the database, and streaming and replaying WAL events is how both Physical and Logical Replication work. Physical replication is used for database replication. Logical Replication, which is the subject of this blog, allows clients to subscribe to data change WAL events. In both cases, replication clients track their progress through the WAL by checkpointing their location, known as the Log Sequence Number (LSN), directly on the primary database. WAL events stored on the primary database can only be discarded after all replication clients, both physical and logical, confirm that they have been processed. If one client fails to confirm that it has processed a WAL event, then the primary node will retain that WAL event and all subsequent WAL events until confirmation occurs.
Simple, right?
Well, the happy path is quite simple, yes. However as you may imagine, this blog post concerns a path that is anything but happy.
The Problem
Before we go on, allow me to paint a simplified picture of our architecture which was experiencing issues with this process:
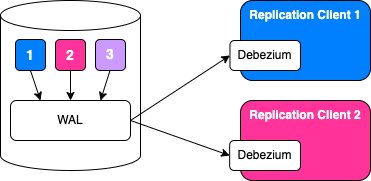
We have a database with multiple tables, denoted here by their different colors: blue (1), pink (2), purple (3), etc. Additionally, we are listening to changes made to the blue and pink tables specifically. The changes are being streamed via Logical Replication to a blue client and a pink client respectively. In our case, these clients are our Postgres-sourced event streaming applications which use Debezium and PgJDBC under the hood to bridge the gap between Postgres byte-array messages and Java by providing a user-friendly API to interact with.
The key thing to note here is that changes from all tables go into the same WAL. The WAL exists at the server level and we cannot break it down into a table-level or schema-level concept. All changes for all tables in all schemas in all databases on that server go into the same WAL.
In order to track the individual progress of the blue and pink replication, the database server uses a construct called a replication slot. A replication slot should be created for each client - so in this case we have blue (upper, denoted 1) and pink (lower, denoted 2) replication slots - and each slot will contain information about the progress of its client through the WAL. It does this by storing the LSN of the last flushed WAL, among some other pieces of information but let’s keep it simple.
If we zoom into the WAL, we could illustrate it simplistically as follows:
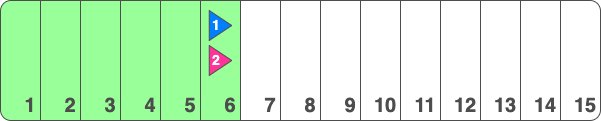
Here, I have illustrated LSNs as decimal numbers for clarity. In reality, they are expressed as hexadecimal combinations of page numbers and positions.
As write operations occur on any of the tables in the database, those write operations are written to the WAL - the next available log position being #7. If a write occurs on e.g. the blue table, a message will be sent to the blue client with this information and once the client confirms receipt of change #7, the blue replication slot will be advanced to #7. However WAL with LSN #7 can’t be recycled and its disk space freed up just yet, since the pink replication slot is still only on #6.
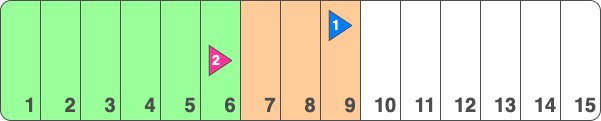
If the blue table were to continue receiving writes, but without a write operation occurring on the pink table, the pink replication slot would never have a chance to advance, and all of the blue WAL events would be left sitting around, taking up space.
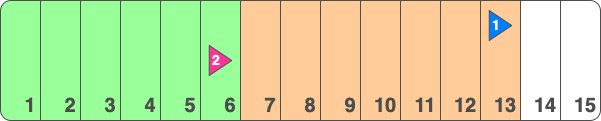
However once a write occurs in the pink table, this change will be written to the next available WAL position, say #14, the pink client will confirm receipt and the pink replication slot will advance to position #14. Now we have the below state:
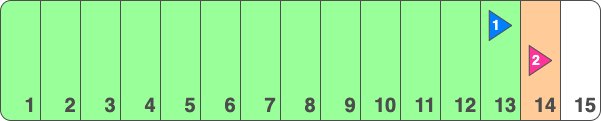
This was the heart of the issue. The pink client is not interested in these WAL events, however until the pink client confirms a later LSN in its replication slot, Postgres cannot delete these WAL events. This will continue ad infinitum until the disk space is entirely used up by old WAL events that cannot be deleted until a write occurs in the pink table.
Mitigation Strategies
Many blog posts have been written about this bug, phenomenon, behavior, call it what you will. Hacky solutions abound. The most popular by far was creating scheduled jobs writing dummy data to the pink table in order to force it to advance. This solution had been used in Zalando in the past but it’s a kludge that doesn’t address the real issue at the heart of the problem and mandates a constant extra workload overhead from now and forever more when setting up Postgres logical replication.
Even Gunnar Morling, the ex-Debezium Lead, has written about the topic.
Byron Wolfman, in a blog post, alludes to the pure solution before abandoning the prospect in favour of the same kludge. The following quote is an extract from his post on the topic:

This was indeed the solution in its purest form. In our case with a Java application as the end-consumer, the first port-of-call for messages from Postgres was PgJDBC, the Java Driver for Postgres. If we could solve the issue at this level, then it would be abstracted away from - and solved for - all Java applications, Debezium included.
Our Solution
The key was to note that while Postgres only sends Replication messages in case of a write operation, it is sending KeepAlive messages on a regular basis in order to maintain the connection between it and, in this case, PgJDBC. This KeepAlive message contains very little data: some identifiers, a timestamp, a single bit denoting if a reply is required, but most crucially, the KeepAlive message contains the current WAL LSN of the database server. Historically, PgJDBC would not respond to a KeepAlive message and nothing would change on the server-side as a result of a KeepAlive message being sent. This needed to change.
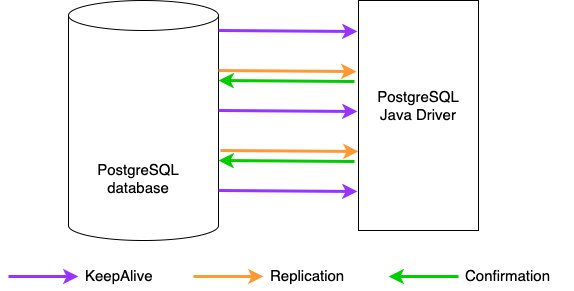
The fix involved updating the client to keep track of the LSN of the last Replication message received from the server and the LSN of the latest message confirmed by the client. If these two LSNs are the same, and the client then receives a KeepAlive message with a higher LSN, the client can imply that it has flushed all relevant changes and that some irrelevant changes are happening on the database that the client doesn't care about. The client can safely confirm receipt of this change back to the server, thus advancing its replication slot position and allowing the Postgres server to delete those irrelevant WAL events. This approach is sufficiently conservative enough to allow confirmation of LSNs while guaranteeing that no relevant events can be skipped.
The fix was implemented, tested, submitted to PgJDBC in a pull request. Merged on August 31st 2023, this fix is scheduled to be released in the 42.7.0 version of PgJDBC.
Rollout
Our Debezium-powered streaming applications support backwards compatibility with functionality that has been removed from newer versions of Debezium. In order to maintain this backwards compatibility, our applications do not use the latest version of Debezium and, by extension, do not use the latest version of PgJDBC which is pulled in as a transitive dependency by Debezium. In order to take advantage of the fix while still maintaining this backwards compatibility, we modified our build scripts to optionally override the latest version of the transitive PgJDBC dependency and we took advantage of this option to build not one, but two Docker images for our applications: one unchanged and another with a locally built version, 42.6.1-patched, of PgJDBC that contained our fix. We rolled this modified Docker image out to our test environment while still using the unchanged image in our production environment. This way we could safely verify that our event-streaming applications continued to behave as intended and monitor the behaviour in order to verify the issue of WAL growth had been addressed.
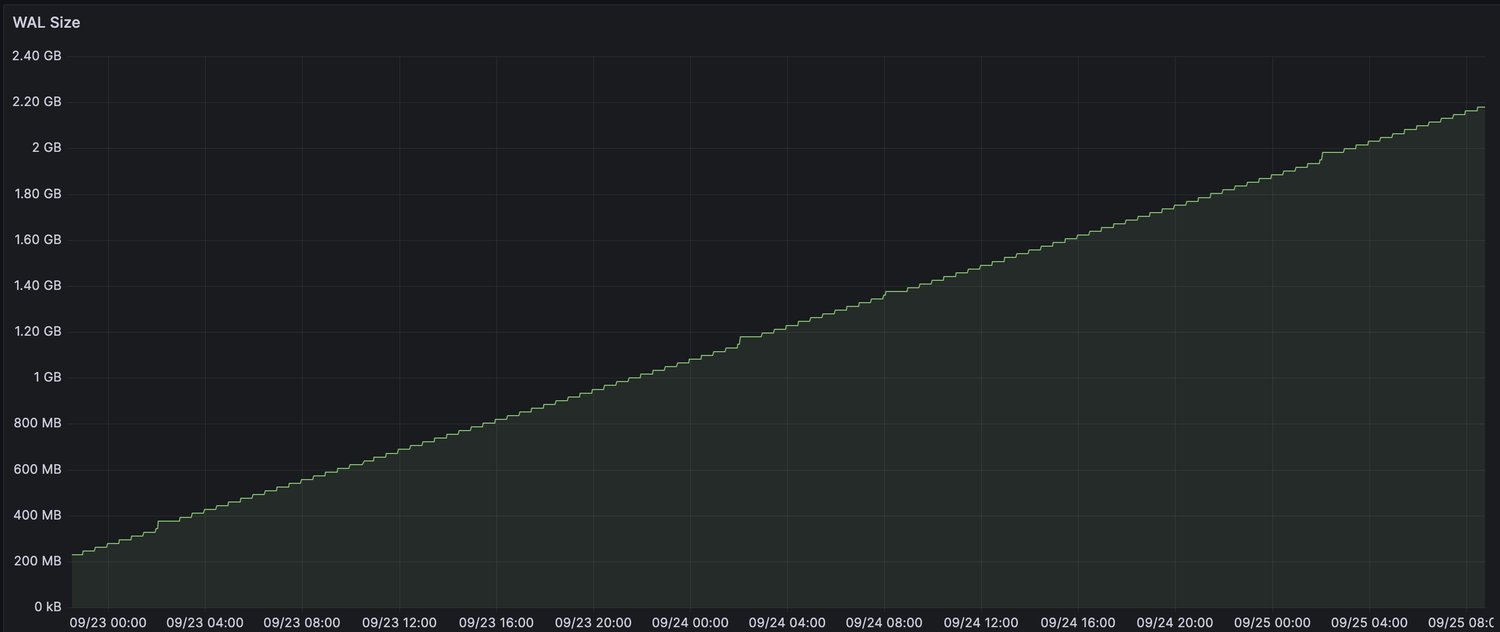
To verify the issue had indeed disappeared, we monitored a graph of the total WAL Size over the course of a few days on a low-activity database. Before the implementation of the fix, it would be common to see the following graph of total WAL size, indicating the presence of the issue over 36 hours:
That same database after the fix now has a WAL Size graph that looks like the below, over the same time range and with no other changes to the persistence layer, service layer or activity:

As the fix itself was designed to be sufficiently conservative when confirming LSNs so that we could guarantee that an event would never be skipped or missed, this evidence was sufficient for us to confidently roll out the newer Docker images to our production clusters, solving the issue of runaway WAL growth for 100s of Postgres-sourced event streams across Zalando. No more hacks required :)
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Software Engineer!



