Search Quality Assurance with AI as a Judge
Deep dive into how Zalando builds a search quality assurance framework with LLM-as-a-judge to evaluate the search quality at scale with high coverage and multi-language support.

Senior Software Engineer
In 2024, Zalando research published a paper on LLM-as-a-judge for search quality assurance at scale. The framework allows scientists and developers to effectively evaluate the semantic relevance of search results of the given search queries at large scale with multi-language support. This capability has strong potential to help the Search engineering team to quickly identify and fix search issues which we will walk through in this post.
Real-world use case: Launching a new country
In 2025 Zalando expanded its fashion store business into 3 new countries: Luxembourg, Portugal and Greece. Ensuring these markets have a good search experience is critical for the success of the launch, but the challenge is how can we do that without any prior search data from real users?
Before using LLM-as-a-judge, the search quality assurance process was heavily reliant on human experts and a manual process as follows:
- Due to the fact that we do not know which search queries may work well or not in the new markets because they are not live yet, we have to draw sample search queries from the existing markets, and translate them if the new market is operating in different language and test the search system manually. Human experts have to annotate error cases, and identify cases where search returns poor quality results.
- Root cause diagnosis in both scenarios (errors / poor results) is also performed by the same experts.
Not only is this process not scalable, but it is also reactive by nature, meaning that issues are only identified after features are launched and users have already experienced them, since we rely on signals coming from real users such as low CTR. For an entirely new country, these signals are by definition not there yet. We need a more proactive approach that ensures quality before launch.
Data-Driven Approach with LLM-as-a-judge
With the recent advances in LLM capabilities, it is now possible to use LLM-as-a-judge techniques to evaluate search quality at scale for new markets before launch. Our aforementioned study shows that it could achieve a high correlation with human judgement, so we decided to build a framework to automate the evaluation process at scale by focusing on the following key principles:
- High test coverage: To gain confidence that the new market will have high quality search feature at launch, we need to have a wide range of tests covering different search scenarios, such as different product categories, different brands and product attributes, popular searches, seasonal or trending products, etc.
- Avoid the need for handcrafted test cases: Manual tests are not very scalable and could be biased. Also it is hard to transfer written test cases from one market to another. To reduce this effort, we want to automate the test generation, while still being able to add or customise the test cases if we need to.
- Multi-language support: All new markets operate in different languages with different linguistic characteristics and we want to cover them well.
- Reproducibility: By nature of the pre-launch testing, we want to be able to re-evaluate the search feature after we applied the fixes to verify that the improvements are effective.
Selection of Test Queries
Using real search queries from existing markets is a good way to go. We need to draw sample test queries from search data which cover as wide range of search scenarios as possible. We should not only take most N frequent query terms, as different forms of queries may mean the same thing, e.g. "Winter boot" and "Boot for winter" are essentially the same search intent. They should belong together and be counted as the same search scenario. Therefore we need a good clustering approach.
Our search operates on a mix of lexical search (text token-based) and semantic vector search. Thus, we have a Named entity recognition (NER) engine to extract a wide range of attributes from the search queries, such as product name, brand, colour, size, season, occassion, material, etc. If we group search queries tagged by the same set of attributes together, we can get a good clustering with meaningful intent.
| NER tags | search queries |
|---|---|
| category: kids, type: jacket, season: winter | Kids Winter Jacket, Winter Jackets for Kids, Kids Jackets Winter |
| category: shoes, brand: nike, type: sneakers | Nike Sneakers, Nike Shoes, Nike Sneaker |
| category: dress, occasion: party, color: black | Black Party Dress, Party Dresses Black, Black Dress for Party |
| category: jeans, fit: slim, color: blue | Blue Slim Jeans, Slim Fit Blue Jeans, Blue Jeans Slim |
| category: boots, material: leather, season: winter | Leather Winter Boots, Winter Boots Leather, Leather Boots Winter |
We can translate these queries to other languages using an LLM. This enables us to reuse search scenarios from existing markets for new markets with different languages, while having translated scenarios keep the same search intents. The example table below shows translated queries in Portuguese (newly supported language) for a few NER tag groups.
| NER tags | original search queries in EN | translated search queries in PT |
|---|---|---|
| category: kids, type: jacket, season: winter | Kids Winter Jacket, Winter Jackets for Kids, Kids Jackets Winter | Jaqueta de Inverno Infantil, Jaquetas de Inverno para Crianças, Jaquetas Infantis de Inverno |
| category: shoes, brand: nike, type: sneakers | Nike Sneakers, Nike Shoes, Nike Sneaker | Nike Sapatilhas, Nike Sapatos, Nike Sapatilha |
| category: dress, occasion: party, color: black | Black Party Dress, Party Dresses Black, Black Dress for Party | Vestido de Festa Preto, Vestidos de Festa Pretos, Vestido Preto para Festa |
| category: jeans, fit: slim, color: blue | Blue Slim Jeans, Slim Fit Blue Jeans, Blue Jeans Slim | Calças de Ganga Azuis Slim, Calças Slim Azuis, Calças de Ganga Slim Azuis |
| category: boots, material: leather, season: winter | Leather Winter Boots, Winter Boots Leather, Leather Boots Winter | Botas de Couro de Inverno, Botas de Inverno em Couro, Botas de Couro Invernais |
To ensure broad test coverage, we sample search queries from existing markets with similar characteristics. Since search intent distribution differs across markets, we select the top N search groups by NER tags (representing search intent/topic) ranked by traffic share. This approach provides a representative test set for the target market and helps identify potential issues in popular search scenarios.
How Does Search Quality Evaluation Work?
Having defined how we select queries above, we can now break down our search quality evaluation process into 2 steps: 1) Generate the test queries with NER clustering and LLM translation, 2) Evaluate the search results with LLM-as-a-judge.
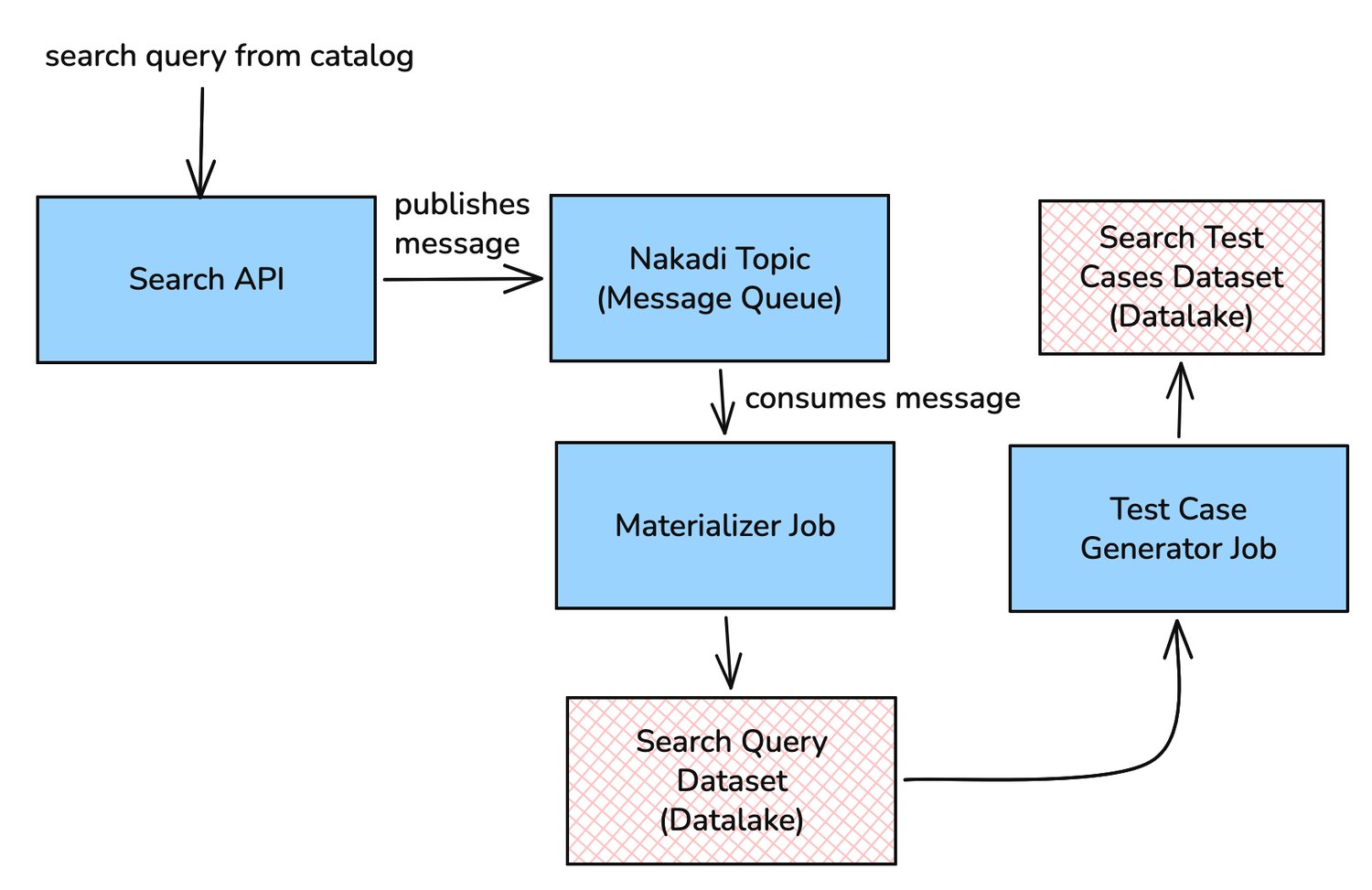
In our search infrastructure, every search request we get in the site is processed by our NER engine, served by our and Search API, and then published to an asynchronous event stream (powered by Nakadi, our RESTful event bus built on top of Kafka queues). At Zalando, we have a large scale data processing platform with continuously running data pipelines that: (1) consume these event streams; (2) process the data; (3) and persist the data into a Data Lake for analysis, reporting, and archival.
We have built test case generation data pipelines that consume search request data from the Data Lake, cluster them by their NER tags, and transform into useful formats ready for tester pipeline to read. The entire flow is built on the OLAP (Online Analytical Processing) paradigm.
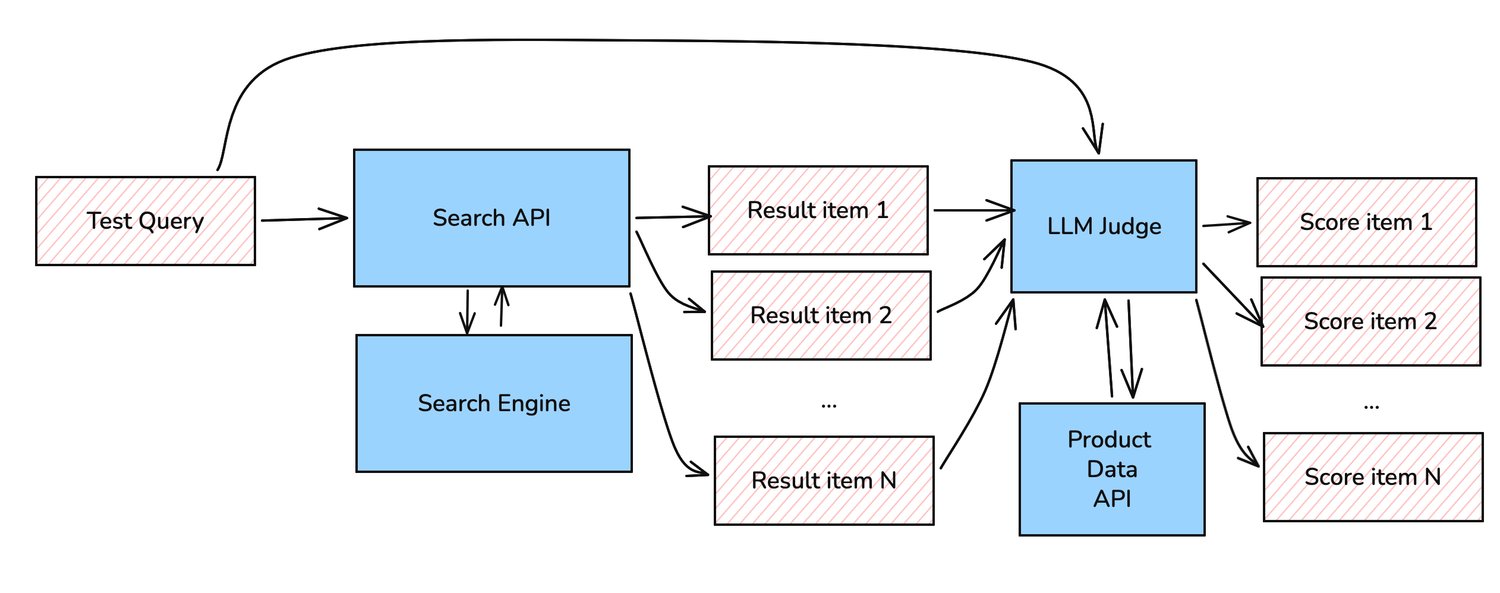
Our LLM-as-a-judge (paper) uses product data and product images for its evaluation context (visual-text). It generalises well across different languages and different search contexts, e.g. by searching "Kids Winter Jacket", the model should give high relevance scores to search results with jacket products of any brands, any colours, etc. from kids categories, according to the product attributes or their images should score. Search results that are just long-sleeve shirts, or adult items, should score lower. The reasoning is generalised and does not require specific prompts to instruct the LLM to look for specific attributes or specific parts of images.

The LLM judge is instructed to give relevance scores for each result item using clear scale criteria. For example, a score of 4 means perfect match, 0 means completely wrong or irrelevant to the search term. Other scores in between represent varying degrees of relevance. This way we can evaluate the overall quality of the result set of each search query segment (represented by the NER tags), while being able to identify wrong articles whose relevance scores are very low which could give engineers a good hint for the root cause of the issue, e.g. wrong product data, misbehaving NER, underperforming ranker, etc.
Production time: The Evaluation Pipelines
Putting the concept together, we have built evaluation pipelines in Apache Airflow to automate the whole process. The pipelines involve the following steps:
- Test query generation: Past queries from existing markets are clustered with NER tags. Clusters with the highest traffic share are selected, and their queries are then submitted to the translation process using LLM if needed. For some markets like Luxembourg, we can directly use the English and French queries from our existing markets without a translation.
- Search result retrieval: This pipeline step spawns a task in our Kubernetes cluster, runs through the test queries and submits them to the search microservice to retrieve the search results. The results are then kept in an in-memory cache for the evaluation step.
- LLM evaluation: The search results are then evaluated by LLM-as-a-judge, which we used GPT-4o during pre-market launch process. The pipeline submits the search results, their product data and images to the LLM and get the relevance scores for each result. The scores are stored in the final evaluation report data.
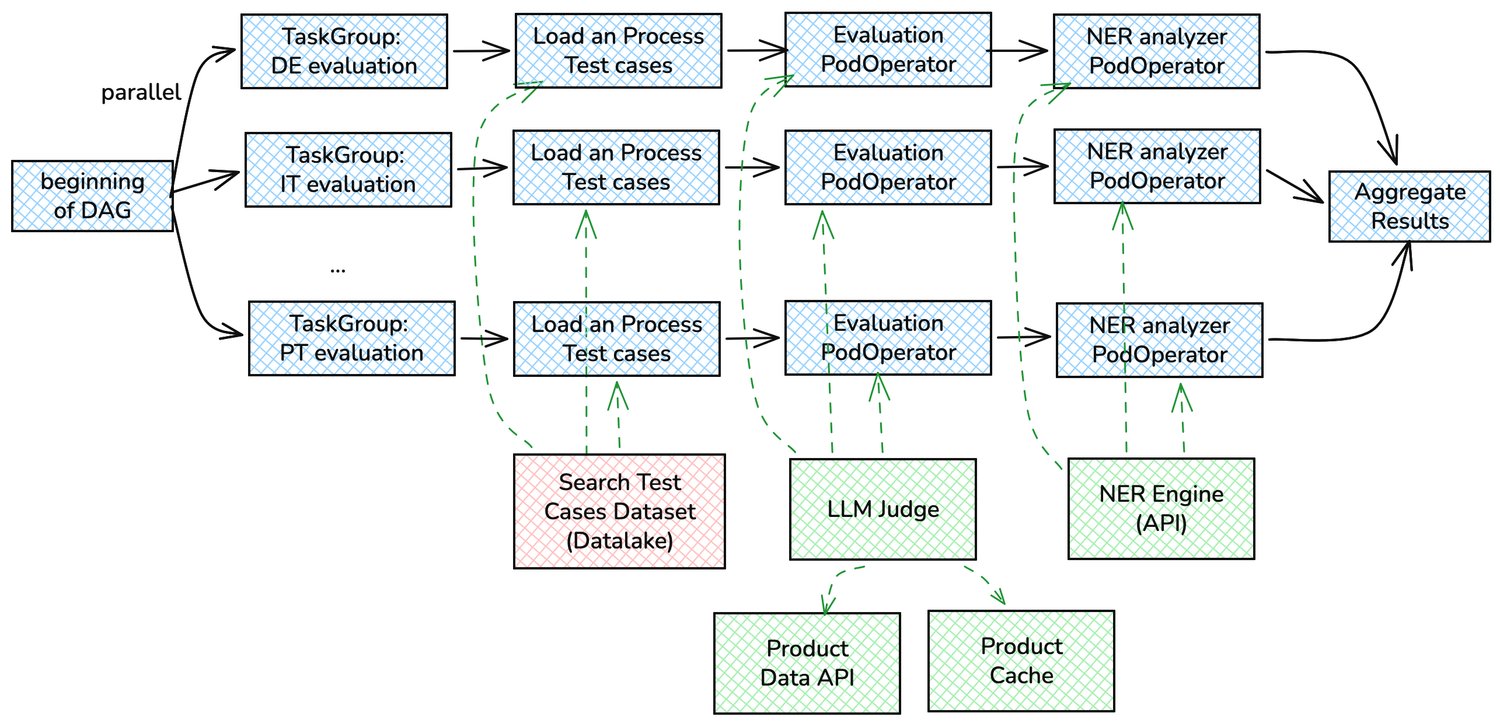
- Taskgroup: We want to be able to evaluate multiple markets in parallel, where each market shares the same flow but with different test queries. Therefore we can implement each evaluation lineage as a task group and put all of them together in the same DAG. This way each task group can run independently in parallel and, once they are all finished, a final task consolidates all evaluation results together.
- PodOperator: The evaluation code is shipped in a docker image and we can run it in our Kubernetes cluster via Airflow using PodOperator. This keeps the DAG code clean and simple, as all complex logic for the evaluation and their dependencies are encapsulated in the image.
- Cache: The search results of different search queries may share the same products and letting the LLM judge to retrieve the same product data and images multiple times would be inefficient and slow. Therefore we put a shared cache (Elasticache) only accessible to the evaluation tasks to store and re-use the product data. This saves time and cost for the evaluation significantly. Instead of calling Product API (5000 x 25) times for 5000 search queries with 25 results, we only need to call it N times where N is the number of unique products in all search results. This N does not scale as much as the number of search queries increases. We also store evaluation results of each (query, product) pair in the cache, so that it reuses the previously evaluated results if the same (query, product) pair appears in other search queries, which further saves time and LLM cost.
- NER engine: During execution, each search query is processed by the NER engine to extract its NER tag attributes. This allows us to compare the NER tags of the original search query and the translated search query, and identify inconsistencies that can lead to search issues, such as missing tags or incorrectly tagged attributes in the new language.
Results
We tested 3 markets with the 1,500 most searched segments in each of them (represented by their NER tags), using the most frequently used search queries in each segment. We could easily identify segments that did not perform well. The example below shows some segments in Portuguese market before launch in which we identified low relevance scores.
| Segment (NER tag group) | Avg relevance score | Details |
|---|---|---|
| CATEGORY=desporto | 1.5 / 4.0 | Queries with "desporto", "desportivo", "desportiva" did not have consistent term filters due to word lemmatization issues. |
| CATEGORY=zapatilhas | 2.4 / 4.0 | Term "tenis", "ténis" (sneaker in portuguese) could not be recognized and did not discover sport shoes in general, due to an ambiguity with sport "tennis" |
| GENDER=mulher CATEGORY=menina | 2.0 / 4.0 | Term "menina", "meninas" could not be recognized so searching for girl articles returned mixed results from any genders and age groups. |
| CATEGORY=fato de treino | 1.2 / 4.0 | Searching for tracksuit "fato de treino" did not show any sport or tracksuit results. |
Using the NER tags as segments helps us categorize the semantically similar search queries together and confirm with confidence when specific categories are not performing well. In the example above for Portuguese results, engineers could investigate further and identify that NER engine may have got a lemmatization issue for terms related to "desporto", "desportivo", "desportiva" which are all related to sport category. The term "tenis" and "ténis" were not recognized because these terms did not exist in our product data, which our NER engine relies on for Lucene-based entity recognition. With one run, we can identify multiple issues at once conveniently.
The same query should have the same NER tags by meaning across different languages. The following example shows results for Greek market, where we can identify NER issues as some terms cannot be recognized. This leads to incorrect search filtering, and the LLM judge observes low relevant results. We can easily confirm missing NER tags by comparing with the original tags from the source language.
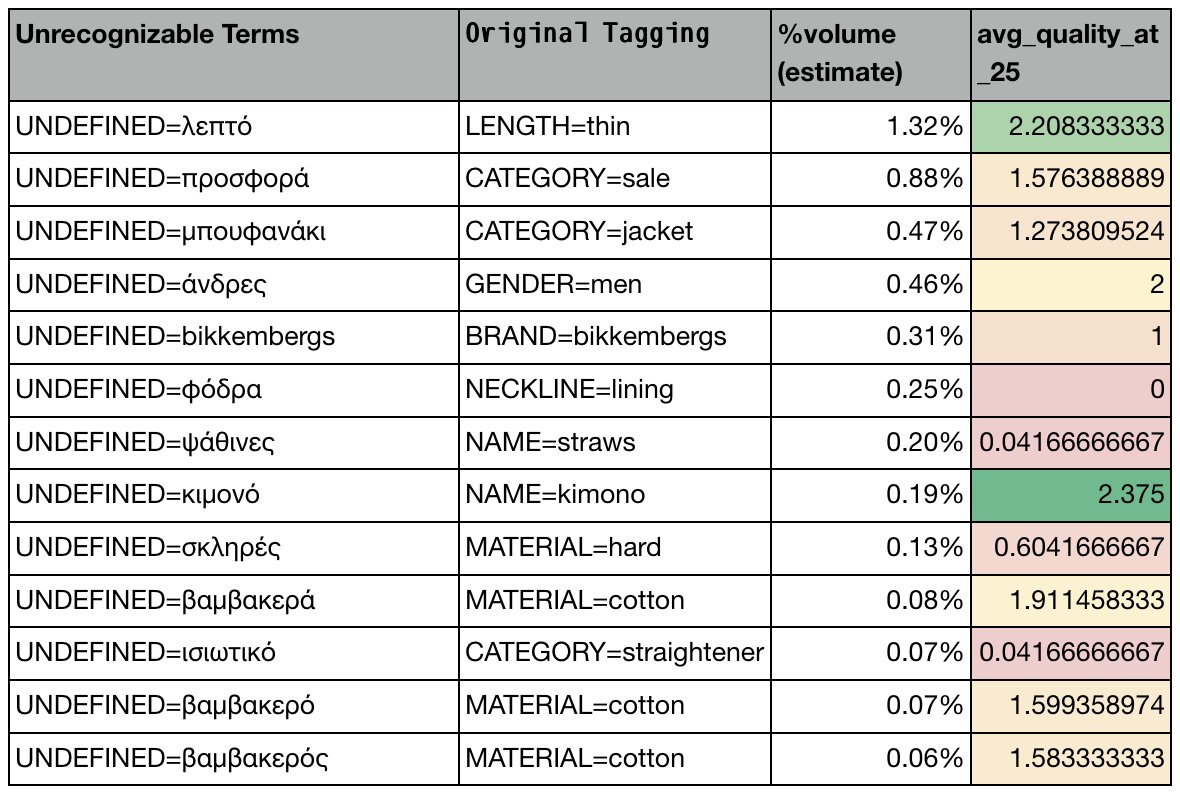
By comparing the original search queries and NER tags with the translated queries with their tags, we could easily identify which NER tags were not recognized in the new languages. Since our search infrastructure uses these NER tags for catalog filtering, search is likely to return low relevance results, that are confirmed by the LLM judge via low relevance scores. This mechanism allowed us to quickly identify NER issues and we could fix them before the go-live in the Greek market.
In conclusion, our evaluation system can either identify or hint at various types of issues. Notable ones include:
- Incorrect product attributes or data: Product categories with incorrect attributes have difficulty surfacing in search results despite different query variations. Multiple NER tag segments with similar meaning but consistently low relevance scores indicate this issue.
- Unrecognized terms or attributes by NER: The evaluation pipeline processes NER tagging (NER analyzer task in the Airflow DAG) to identify unrecognized terms. This helps validate spell correction and lemmatization in new languages, and determines whether to index missing terms for searchability.
- Undiscoverable products or categories: This helps us identify if a brand, a product family, or a category is not discoverable by analyzing multiple search segments that share the same product tags from NER (example in the table below).
| Segment (NER tag group) | Avg relevance score |
|---|---|
| BRAND=foo CATEGORY=yoga | 1.8 / 4.0 |
| BRAND=foo CATEGORY=leggings | 1.6 / 4.0 |
| BRAND=foo GENDER=mulher CATEGORY=tops | 1.9 / 4.0 |
| BRAND=foo CATEGORY=fato de treino | 1.7 / 4.0 |
| BRAND=foo CATEGORY=jackets MATERIAL=nylon | 1.5 / 4.0 |
The example in the table above shows that multiple segments with brand Foo show low search relevance scores. This may highlight that the product data may have quality issues, e.g. missing or wrong attributes, which leads to the issue that these products are less discoverable by search. This helps us quickly identifying which products or categories may need a deep check and fix before launch.
Cost of evaluation
The cost per one full run nets around 250 USD, which mainly comes from GPT-4o completion API cost. This is very cost efficient for the scale of 1,500 search segments with 25 results each. Especially so when considering the alternative of human evaluation, which also would take days. One run with our framework takes around 3-5 hours on average. Please refer to the (paper) for more details of the LLM vs. human cost for annotation.
Bottom Line
Using LLM as a judge helps us evaluating the search quality at scale with high coverage and multi-language support. The investment to set up the infrastructure was a one-time cost, and no handcrafted test cases were necessary. With this setup, we can re-evaluate our search quality as many times as we want. It gave us confidence that our search engine was ready for launching new markets. Finally, we can now also perform automated in depth validation of existing markets, which enables us to proactively identify regressions and otherwise uncaught issues.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Machine Learning Engineer!








