Rejecting Invalid Ingress Routes at Apply Time
How Zalando used Skipper as a validating admission webhook to reject invalid filters and predicates at apply time, and what it took to make that safe on the Kubernetes control-plane path.

Software Engineer
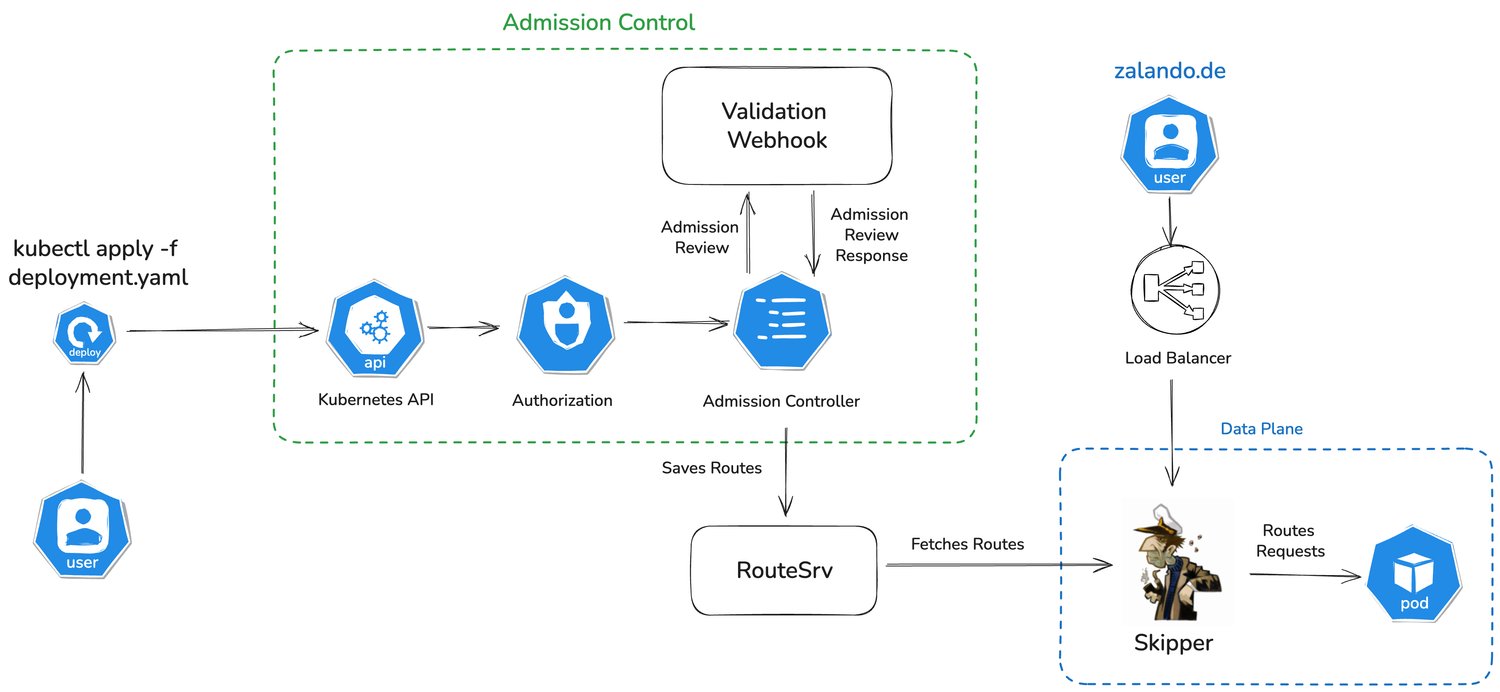
Skipper is an open-source HTTP router and reverse proxy that can also run as a Kubernetes ingress controller. At Zalando, it is the component that turns Ingress and RouteGroup configuration into live routing behavior. Its routing model is powerful because requests can be matched by predicates, transformed by filters, and then forwarded to backends.
The downside is that Kubernetes has no understanding of Skipper-specific filters and predicates, and therefore cannot validate them through standard Admission Control. For example, a route might reference a non-existing predicate, use a filter with invalid parameters, or define a backend that cannot be parsed. Kubernetes accepts this configuration because it is syntactically valid, but from Skipper’s perspective, the route is broken.
At Zalando scale, these invalid routes are critical. We run Skipper across 250+ Kubernetes clusters, with 15k+ ingresses, ~200k routes, and 500k-2M RPS. At that size, even 1% invalid routes is not background noise. It is real production risk.
The goal was simple: reject invalid Skipper routing configuration during kubectl apply.
How Skipper sees a route
A Skipper route is essentially:
routeId: Predicates -> filters -> backend
The route ID names the route. Predicates decide whether a request matches it. Filters modify the request or response. The backend defines where the traffic goes next.
A simplified example:
canary:
Host("^edge[.]internal$") && Header("X-Canary", "true")
-> setPath("/v2")
-> "http://checkout:8080";
This model is one of the reasons Skipper works well as an ingress controller. It translates Ingress and RouteGroup resources into eskip routes and gives teams a rich routing language without requiring a separate proxy configuration format.
At the same time, it means many routing mistakes are invisible to Kubernetes itself. A typo like Headr("X-Canary", "true") instead of Header(...) is still just a string from the API server's point of view. The manifest can be structurally valid while the resulting Skipper route is not.
The validation webhook provided basic semantic checks, which was useful, but it did not validate filters and predicates against Skipper's runtime registry.
For developers, the feedback loop was poor. The apply looked successful, while the actual routing problem surfaced later and in a different place.
Letting Skipper validate Skipper
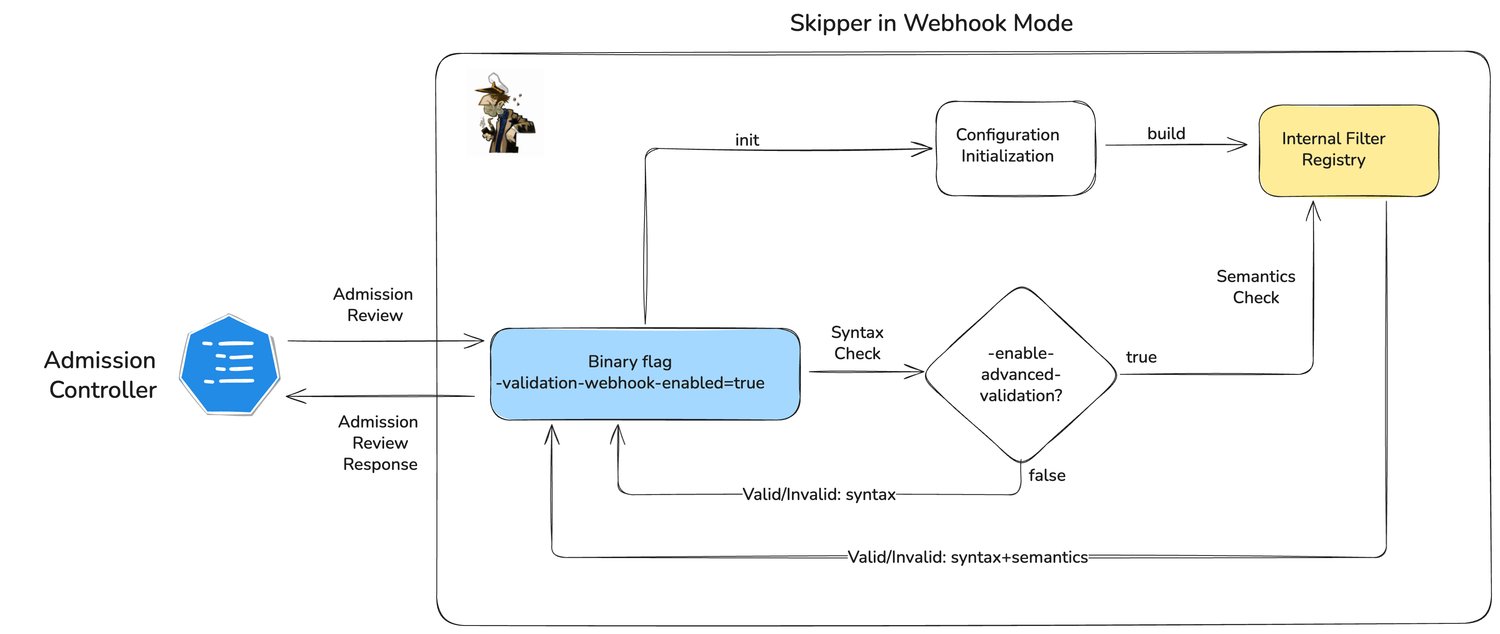
The key design choice was to stop treating route validation as a generic string-parsing problem and instead reuse Skipper's own validation logic on the admission path.
For matching CREATE and UPDATE requests on the resources we care about, the API server sends an AdmissionReview to the validating webhook. The webhook extracts the Skipper-specific configuration from the object and validates it using Skipper's own filter registry, predicate specifications, route validation, and backend checks.
This changes the contract importantly. The webhook no longer answers: "Does this string parse?" - instead it answers: "Would Skipper accept this route?"
That is the difference between basic admission checks and admission-time route validation.
What happens during kubectl apply now
From the user's perspective, the flow is straightforward.
- An engineer or a deployment system submits an
IngressorRouteGroup. - Kubernetes performs the usual authentication, authorization, and built-in object validation.
- For matching resources and operations, the API server calls the validating webhook over HTTPS.
- Webhook runs Skipper validation on the relevant route configuration and returns either allow or deny.
- Only valid objects are persisted.
If the route configuration is invalid, the request is rejected immediately and the error is returned to the caller. The failure stays on the deployment path, which is where it is most useful.
Useful errors at applied time
Fast rejection is only useful if the error message is actionable.
For example, consider this Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: demo-invalid-unknown-predicate
namespace: default
annotations:
zalando.org/skipper-predicate: NonExistingPredicate()
spec:
rules:
- host: demo.example
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: demo-app
port:
number: 8080
When this object is applied, the rejection can be explicit:
➜ kubectl apply -f simple-app.yaml
Error from server: error when creating "simple-app.yaml": admission webhook "ingress-admitter.teapot.zalan.do" denied the request: invalid "zalando.org/skipper-predicate" annotation: unknown_predicate: unknown_predicate: predicate "NonExistingPredicate" not found
The same applies to invalid filter parameters or backend problems. The important part is not just that the request is rejected, but that the engineer who made the change can fix it without going hunting through runtime logs.
Rollout strategy
This was the most challenging part.
The validation logic itself was relatively direct. The harder part was making the rollout seamless for users. Even if a problem here does not affect existing customer traffic, it could still block Kubernetes writes. In practice, that means blocked CI/CD pipelines, delayed service updates, and engineers unable to ship changes. Existing traffic keeps flowing, but change stops.
We approached the rollout as a control-plane change. First, I added metrics that made invalid routes visible during rollout. The most useful signal was skipper_route_invalid{route_id, reason}, which told me exactly which route failed validation and why. That made it much easier to distinguish real configuration mistakes from false positives in the validator.
Then I rolled the feature tier by tier across clusters. After each rollout step, we watched webhook health, latency, denials, and invalid-route metrics before moving to the next tier. The goal was not only to prove that validation worked, but also that it stayed predictable under normal production usage.
We also kept advanced validation behind the -enable-advanced-validation feature flag. That gave us a fast rollback path without removing the webhook itself. During the rollout, we did encounter cases where some routes were rejected even though they should have been accepted. In those cases, we turned advanced validation off, fixed the issues, and continued the rollout once the behavior was correct again.
I later presented this solution at an internal Zalando conference, and one of the first questions was how teams could enable it in their clusters. The satisfying part was answering that they did not need to do anything, because it was already enabled. That is probably the best possible result for this kind of rollout.
Operational outcome
The biggest improvement was not a benchmark number. It was moving failure to the right place.
Before, invalid route configuration could be accepted by Kubernetes and only discovered later in the routing layer. In practice, that meant people showed up in support channels asking why their requests don't work.
After the webhook change, invalid route configuration is rejected during deployment, before it becomes part of the cluster state. That made the feedback loop much faster and kept the error attached to the change that caused it.
The implementation is now part of open-source Skipper, available from v0.24.18, so the same pattern can be reused outside Zalando as well.
We're hiring! Do you like working in an ever evolving organization such as Zalando? Consider joining our teams as a Backend Engineer!



